
קינפוג ה-DB ושימוש בקובץ קונפיגורציה
אפשרויות קונפיגורציה של mongo shell
פרק 2: התחלת עבודה מהירה עם MongoDB
הבנת ה-schema וסוגי הנתונים ב-mongodb
בדיקת סוג הנתונים - validation
פרק 3: אפשרויות קונפיגורציה של mongoDB
ה-Storage Engine ו-WriteConcern
שינוי איבר במערך ע"י שימוש באופרטור $
שינוי כל האיברים במערך ע"י שימוש באופרטור []$
הוספת איבר למערך ע"י שימוש ב-push או addToSet
הוספת מספר איברים למערך ע"י שימוש ב-push עם-each וכן שימוש ב-sort, slice
הסרת איברים ממערך ע"י שימוש ב-pull ו-pop
אינדקסים מורכבים - compound indexes
שיפור הפקודה sort בעזרת אינדקס
שימוש באינדקס לקנפג שדה ייחודי (unique)
אינדקס חלקי כפתרון לבעיית אינדקס ייחודי
איך מונגו בוחר את שיטת החיפוש - plan?
פרק 9: שימוש מתקדם בעזרת aggregation framework
אז למה בעצם להשתמש ב-aggregate
שימוש ב-push, unwind, addToSet ליצירת מערך
פעולות נוספות על מערך slice, size
סינון איברים במערך לפי תנאי ע"י filter
חלוקת המידע לקבוצות ע"י האופרטור bucket
שמירת המידע המתקבל מ-aggregate ע"י אופרטור out
פרק 10: קצת על ניהול מערכת MongoDB
פרק 1: הקדמה
לא ניכנס לכל הפרטים של תהליך ההתקנה של MongoDB כיון שהוא משתנה לפי מערכת הפעלה וכנראה גם ישתנה במשך הזמן. הכי טוב זה לבדוק באינטרנט באתר הרשמי של MongoDB.
רק אציין כמה נקודות חשובות:
- אני עובד על windows 11 עם MongoDB גרסה 6.0.5.
- מהאתר של MongoDB אתם צריכים להוריד משהו שנקרא Community Server. זה בעצם ה-DB שאיתו אנו עובדים. נכון להיום זה נמצא פה https://www.mongodb.com/try/download/community
לאחר התקנה רגילה על windows (אם לא שיניתם את האפשרויות הדיפולטיביות בתהליך ההתקנה) MongoDB ירוץ כתהליך נפרד ברקע.
ניתן לראות אותו ב-services של windows (ליחצו במקלדת על על windows key וחפשו "services" ואז enter. יפתח לכם כלי שמציג את כל ה-services שרצים עכשיו ברקע) חפשו שם את MongoDB ובלחיצה עליו אפשר לעצור אותו וגם להריץ מחדש.
וכדי לתקשר איתו נשתמש ב- MongoDB shell. חפשו אותו באינטרנט והורידו אותו.
במצב רגיל הוא אמור להתחבר לתהליך ה-MongoDB שרץ ברקע בלי שום קונפיגורציה מיוחדת. פשוט לוחצים על הקובץ mongosh.exe והוא עולה (אחרי שהוא עלה לוחצים enter כדי להשתמש ב-connection string הדיפולטיבי והוא מחובר ל-MongoDB).
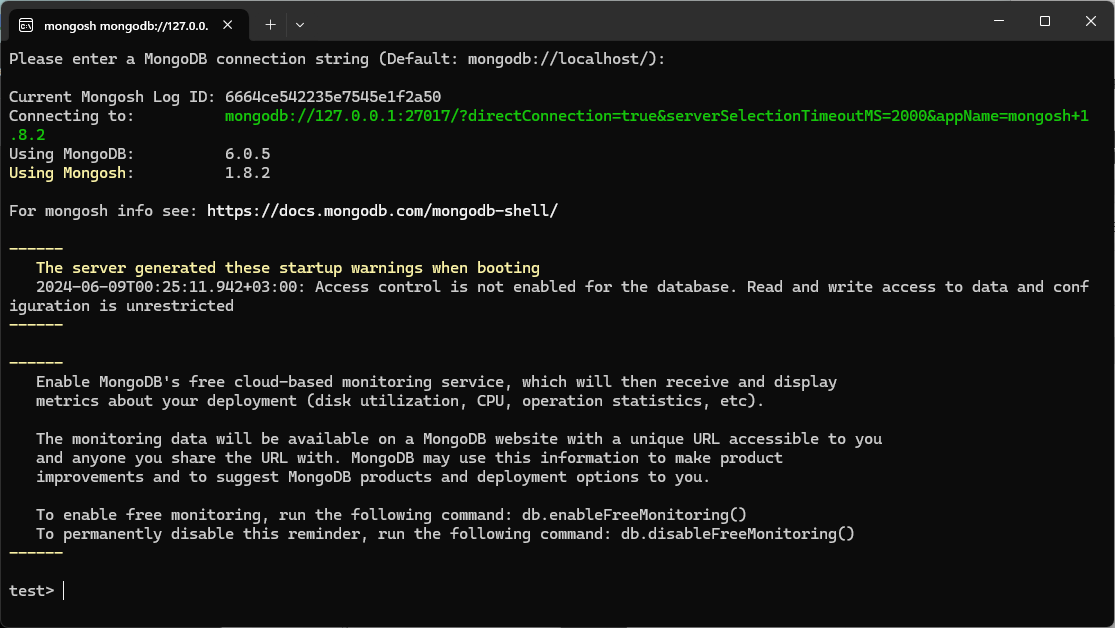
כדי לבדוק שאנחנו מחוברים ל-MongoDB נריץ פקודה שמדפיסה לנו את שמות מסדי הנתונים שיש לנו בשרת:
test> show dbs admin 40.00 KiB config 108.00 KiB local 40.00 KiB
קינפוג ה-DB ושימוש בקובץ קונפיגורציה
ברגע שהתקנו את MongoDB ב-windows הוא כבר רץ ברקע. לחילופין אם ניגש בשורת הפקודה לספריית bin של MongoDB אפשר להריץ משם את הקובץ mongod והוא יריץ את MongoDB.
כשכותבים את הפקודה mongod אפשר לתת לה כל מיני אפשרויות וכך לקנפג את שרת ה-MongoDB שאנחנו הולכים להריץ.
דרך נוחה יותר היא שימוש בקובץ קונפיגורציה. אפשר ליצור אותו בכל מיקום. השם שלו ב-windows יהיה בד"כ mongod.cfg, ואילו בלינוקס mongod.conf. והוא נכתב בפורמט YAML.
דוגמה לקובץ קונפיגורציה אפשר לראות כאן:
systemLog: destination: file path: "/var/log/mongodb/mongod.log" logAppend: true storage: journal: enabled: true processManagement: fork: true net: bindIp: 127.0.0.1 port: 27017 setParameter: enableLocalhostAuthBypass: false
כדי להריץ את מונגו כך שיקונפג לפי קובץ הקונפיגורציה שלנו נשתמש בפקודה:
mongod -f \path\to\my\config\file\mongod.cfg
אפשרויות קונפיגורציה של mongo shell
כדי להריץ את ה-MongoDB shell אפשר פשוט להריץ את הקובץ mongosh.exe.
לפני שמריצים אותו אפשר לראות את כל האפשרויות של קינפוג ה-shell על ידי:
mongosh --help
כדי לחבר את ה-shell לפורט שונה מהדיפולט נשתמש ב:
mongosh --port 1234
ניתן גם להוסיף שם משתמש (ע"י u-) וסיסמה (ע"י p-), אם ה-DB שלנו מוגדר כך שהוא דורש שם משתמש וסיסמה.
לאחר שאנחנו בתוך MongoDB shell אפשר להריץ help כדי לקבל רשימה של פקודות שימושיות בתוך ה-shell.
כדי לקבוע באיזה DB נשתמש נריץ את הפקודה use ואז שם ה-DB:
use testdb
כדי לראות רשימה של פקודות שימושיות בתוך ה-DB נכתוב:
db.help()
ואפשר גם לקבל רשימה של פקודות עבור collection:
db.someCollection.help()
פרק 2: התחלת עבודה מהירה עם MongoDB
כדי להשתמש ב-DB מסוים נכתוב:
use dbName
אם הוא קיים מונגו ישתמש במה שקיים. ואם הוא לא קיים מונגו יצור אותו ברגע שנתחיל לכתוב לתוכו.
כדי לראות את ה-collections הקיימים ב-DB נכתוב:
show collections
ה-collection, וה-document נוצרים אוטומטית ברגע שכותבים לתוכם לכן לא צריך ליצור אותם במפורש.
db.collectionName.insertOne({
"name": "Rafael",
"age": 40,
"married": true
})כדי לראות את כל המידע ב-collection:
db.collectionName.find()
אם ההדפסה צפופה ולא ברורה אפשר להשתמש ב-pretty:
db.collectionName.find().pretty()
ניתן למחוק DB ע"י:
db.dropDatabase()
ה-DB שימחק הוא זה שאנחנו משתמשים בו כרגע (הפקודה use dbName קובעת באיזה אנחנו משתמשים).
ניתן למחוק collection ע"י:
db.collectionName.drop()
כל עוד שם השדה (ה-key) לא כולל רווחים, אפשר לכתוב אותו ללא גרשיים (בדוגמה הבאה name, city, number):
db.collectionName.insertOne({
name: "Dror",
city:"Petah Tikva",
number: 12
})ניתן לשמור באותו collection מסמכים בעלי מבנה (schema) שונה, זה בעצם הרעיון המרכזי ב-DB שהוא לא רלציוני (בניגוד ל-DB רלציוני כמו SQL). כמובן שכדאי לשמור על מסמכים עם מבנה זהה כמה שיותר ולהכניס שדות שנצרכים למסמכים מסוימים לפי הצורך.
מאחורי הקלעים מונגו שומר את המידע בפורמט שנקרא bson שזה binary json מה שמייעל מבחינת מהירות וזיכרון. בכל מקרה מבחינת שימוש במונגו, אנחנו משתמשים רק ב-json.
כל פעם שמכניסים מסמך חדש, מונגו מוסיף לו בצורה אוטומטית שדה שנקרא id_ מסוג ObjectId, עם ערך
ייחודי.
אפשר גם לקבוע בעצמנו בצורה מפורשת מה יהיה ה-id_. למשל:
db.collectionName.insertOne({
name: "Noam",
city:"Petah Tikva",
_id: "abc-123"
})ה id_ יכול להיות string או מספר אבל חייב להיות ייחודי. אם ננסה להשתמש בid_ שכבר קיים, נקבל שגיאה.
כדי למחוק מסמכים נשתמש בפקודת delete. אם נירצה למחוק מסמך אחד נשתמש ב-deleteOne וניתן לו פילטר שיגדיר מה למחוק:
db.collectionName.deleteOne({age: 21})
בדוגמה הזו ימחק המסמך הראשון שימצא עם שדה age ששווה ל-21.
כדי למחוק את כל המסמכים ב-collection נוכל לכתוב:
db.collectionName.deleteMany({})
כדי לעדכן מסמך נשתמש ב-updateOne. אם ננסה להשתמש בו ככה:
db.collectionName.updateOne({age: 21}, {hight: 1.80})
נקבל שגיאה על "atomic operator". השגיאה הזו אומרת שצריך להשתמש באופרטור של מונגו. אופרטורים הם פונקציות של מונגו שמבצעות פעולה על הנתונים. נלמד על הרבה מהם בהמשך. כל האופרטורים מתחילים בסימן של דולר.
אז כדי לבצע את הפקודה הקודמת בצורה נכונה נכתוב:
db.collectionName.updateOne({age: 21}, {$set: {hight: 1.80} })
בדוגמה הזו הוא יוסיף את השדה הזה אם הוא לא קיים, ויעדכן אותו אם הוא כן קיים.
כדי לעדכן את כל המסמכים אפשר להשתמש ב-updateMany עם פילטר שהוא אובייקט ריק:
db.collectionName.updateMany({}, {$set: {hight: 1.80} })
ואם עכשיו נירצה למחוק את כל המסמכים שיש להם שדה מסוים נוכל לכתוב:
db.collectionName.deleteMany({hight: 1.80})
כדי להכניס מסמך נשתמש ב-insertOne וכדי להכניס יותר ממסמך אחד נשתמש ב-insertMany:
db.collectionName.insertMany([
{
name: "Noam",
city:"Petah Tikva",
},
{
name: "Dror",
city:"Yerushalim",
age: 30
}
])נרחיב קצת על find
ניתן למצוא מסמכים עם ערך מסוים בשדה מסוים למשל:
db.collectionName.find({age: 30})
כך נקבל את כל המסמכים שיש להם שדה age עם ערך 30.
ניתן גם למצוא לפי תנאי יותר מורכב על ידי שימוש באופרטורים. למשל כדי למצוא את כל המסמכים שיש להם שדה age שגדול מ-30:
db.collectionName.find({age: {$gt: 30}})
האופרטור gt זה ראשי תיבתו של greater than. שימו לב שהאופרטור חייב להיות בתוך אובייקט (סוגריים מסולסלים).
אפשר גם לבדוק כמה מסמכים נמצאו ע"י שימוש ב-count:
db.collectionName.find({age: {$gt: 30}}).count()
ה-cursor
אם יש לנו הרבה מסמכים ב-collection, בפלט של פקודת find לא נראה את כולם. אנחנו נראה משהו כמו 20 ראשונים ויהיה כתוב שאם רוצים לראות עוד צריך להריץ את הפקודה it או משהו כזה.
הסיבה לכך היא שפקודת find לא מחזירה לנו מערך של כל המסמכים אלא cursor למסמכים שבעזרתו אפשר לגשת אליהם. הרעיון מאחורי זה הוא שב-DB יש בד"כ המון מסמכים ואנחנו לא באמת רוצים שהפקודה הזו תחזיר לנו את כולם. זה יציף אותנו. לעומת זאת בעזרת ה-cursor נוכל לעשות כל מה שנרצה בצורה יעילה.
אם בכל זאת רוצים לקבל את כל המסמכים כמערך נשתמש על גבי ה-cursor ב-toArray:
db.collectionName.find().toArray()
דרך נוחה לעשות פעולה על כל אחד מהמסמכים ב-JavaScript היא ע"י forEach:
db.collectionName.find().forEach((document) => {printjson(document)})
כפי שרואים, ב-JavaScript ניתן להשתמש ב-arrow function כדי לבצע פעולה על כל מסמך ב-collection.
פקודת forEach בעצם שולפת בכל איטרציה רק מסמך אחד ופועלת עליו. היא לא טוענת לזיכרון את כל המסמכים, וזה חוסך לנו במשאבי זיכרון.
לאחר שהבנו מה זה cursor, אפשר גם להבין למה פקודת pretty נכשלת על findOne ומצליחה על find. פקודת pretty היא פקודה של ה-cursor וכיון ש-findOne לא מחזירה cursor (אלא מחזירה את המסמך עצמו) לכן פקודת pretty נכשלת בה.
החזרת חלק מהשדות - projection
לא תמיד אנחנו צריכים את כל השדות שיש במסמכים. כמובן שאפשר לקבל הכל ואז בקוד שלנו להשתמש רק במה שאנחנו רוצים. אבל צורה יעילה יותר היא פשוט לומר למונגו להחזיר לנו רק שדות מסויימים וכך נחסוך רוחב פס והפקודה תהיה מהירה יותר. הפרמטר הראשון של find הוא הפילטר ולאחריו ה-projection. ולכן אם אנחנו רוצים לקבל חזרה בכל מסמך רק את השדה name נוכל לכתוב:
db.collectionName.find({},{name: 1})
הערך 1 אומר שאנחנו רוצים את השדה הזה.
מה שבפועל נקבל זה את השדה name אבל גם את id_. וזה כיון ששדה ה-id_ הוא שדה מיוחד שבדיפולט מוחזר. אם אנחנו לא רוצים אותו נצטרך בצורה מפורשת לכתוב את זה ע"י הערך 0:
db.collectionName.find({},{name: 1, _id: 0}).pretty()
נרחיב קצת על update
ל-update יש שלוש פקודות - update, updateOne, updateMany.
כבר ראינו לעיל את השימוש ב-updateOne:
db.collectionName.updateOne({age: 21}, {$set: {hight: 1.80} })
כאשר החלק הראשון הוא הפילטר והחלק השני הוא האופרטור. הפקודה הזו תעדכן רק מסמך אחד. הראשון שימצא ובו שדה hight עם ערך 1.8.
בניגוד אליה, פקודת ה-update מעדכנת הרבה מסמכים יחד, כמו פקודת updateMany. אם כן מה בעצם ההבדל ביניהם?
את ההבדל ניתן לראות אם לא נשתמש באופרטור. למשל בצורה הבאה:
db.collectionName.update({age: 21}, {hight: 1.80})
צורה כזו היתה מקבלת שגיאה עבור updateOne ו-updateMany. אבל עבור update היא עובדת ללא שגיאה, אבל התוצאה המתקבלת היא:
{ _id: 642493c78332d30258733079, hight: 1.8 }
מה שבעצם קרה זה שהפקודה הזו החליפה את כל המסמך מלבד את ה-id_. היא לא רק עדכנה שדה מסוים, אלא את כל המסמך. אם המסמך היה עם 20 שדות לפני הפעולה, אז עכשיו יש לו רק שתי שדות, id, hight.
אם היינו משתמשים באופרטור set אז הוא היה עובד כמו updateMany ומעדכן רק שדה בתוך המסמך ולא מחליף את כל המסמך. חשוב להבין את הנקודה הזו ולהשתמש בפקודה בצורה נכונה.
כדי שהקוד שלנו יהיה יותר ברור, מומלץ שלא להשתמש בפקודה update, וכאשר רוצים באמת להחליף מסמך שלם להשתמש ב-replaceOne בצורה הבאה:
db.collectionName.replaceOne({age: 21}, {hight: 1.80, name: Yaakov, jinji: true})
שימוש ב-embedded documents
במונגו ניתן להכניס מסמך בתוך מסמך אחר (מה שנקרא nesting). ואפשר גם להכניס מסמך בתוך מסמך בתוך מסמך. והרבה יותר אפילו. הגבול העליון הוא עד 100 רמות של nesting. זה הרבה מאוד ולא ראיתי מקרה שצריך כל כך הרבה רמות.
הגבלה נוספת על מסמכים היא שהגודל המקסימאלי של כל מסמך הוא 16MB. זה נשמע לא הרבה אבל כיון שאנחנו מכניסים למסמכים רק טקסט זה די הרבה.
דוגמה פשוטה של nesting:
db.collectionName.updateMany({}, {$set: {status: {married: true, numberOfKids: 5}}})
בדוגמה הזו נעדכן את כל המסמכים שיהיה להם שדה שנקרא status שהוא בעצמו מסמך/אובייקט עם שני שדות.
ניתן לראות את הפרטים לגבי ההגבלות של mongoDB בלינק הזה
https://www.mongodb.com/docs/manual/reference/limits/
הבנת ה-schema וסוגי הנתונים ב-mongodb
במונגו אין הכרח שב-collection מסוים כל מסמך יהיה עם אותם שדות. אפשר אפילו שלכל מסמך יהיו שדות שונים לגמרי. אבל בד"כ בעולם האמיתי אנחנו רוצים אחידות מסוימת.
אפשר לומר שיש 3 אפשרויות לאחידות השדות:
1. אחידות מלאה - לכל מסמך יש את אותם השדות
{name: table, price: 200}
{name: chair, price: 100}
2. אחידות חלקית - יש כמה שדות שיש לכל המסמכים, ולחלק מהמסמכים יש שדות נוספים
{name: table, price: 200}
{name: chair, price: 100, color: red}
3. ללא אחידות - לכל מסמך יש שדות שונים
{name: table, price: 200}
{title: chair, color: red}
סוגי הנתונים הם:
- Text
- Boolean
- Number
- Integer (int32)
- NumberLong (int64)
- NumberDecimal - דיוק גבוה של עד 44 מקומות אחרי הנקודה. אם ננסה לכתוב מספר גדול יותר מ-64 ביט, חלק מהמספר יחתך ולא ישמר. ולכן למספרים גדולים מאוד צריך דרך אחרת כמו למשל שמירה שלהם כ-string.
- ObjectId - סוג מיוחד של מונגו. זה הסוג שאנחנו מקבלים אוטומטית לשדה ה-id_ שנוצר לכל מסמך. המאפיינים שלו הם ייחודיות (כל id שונה) ושכל אחד שיווצר יהיה בסדר עולה לעומת אלו שנוצרו לפניו. ולכן אפשר להשתמש בו לצורך מיון.
- ISODate - לצורך תאריכים
- Timestamp - מציין תאריך ב-unix time שזה בעצם מספר המילי שניות משנת 1970. הערך נשמר ב-signed 64-bit integer. ולכן מספר שלילי יתייחס לזמן שלפני שנת 1970. השדה הזה תמיד ייחודי. אפילו אם ניצור שני מסמכים באותו זמן הם יקבלו ערך שונה.
- Embedded document
- Array
פירוט מלא על כל סוגי הנתונים ניתן למצוא כאן
ttps://www.mongodb.com/docs/manual/reference/bson-types/.
יחסים בין נתונים
במקרים רבים נצטרך להתייחס ב-document אחד ל-document אחר. ישנן שתי דרכים לעשות זאת.
1. על ידי nested document
2. על ידי reference
למשל אם יש לנו משתמש (users collection) שרוכש מוצרים. אז ניתן להכניס את כל המוצרים שהוא רכש תחת ה-document של המשתמש, בצורה הזו:
users collection
{
user: "Rafael",
products: [{name: "camera", price: 99}, {name: "book", price: 29}]
}
או להכניס reference ל-products collection של כל מוצר שהוא רכש :
user collection
{
user: "Rafael",
products: ["id1", "id2"]
}
כאשר כל id מייצג reference למוצר שנמצא בקולקשיין אחר. במקרה הזה למשל הוא יהיה בקולקשיין שנקרא products.
{
{
_id: "id1",
name: "camera",
price: 99
},
{
_id: "id2",
name: "book",
price: 29
}
}
ההחלטה תלויה בצרכים של המערכת שלנו. אם המערכת שלנו משנה הרבה פעמים את תיאור המוצרים כדאי להשתמש בשיטה השניה, כיוון שכך נצטרך לשנות את פרטי המוצר רק ב-document של המוצר ולא בכל המשתמשים. בנוסף, כיון שמוצר מסוים יכול להירכש על ידי מספר משתמשים (מה שנקרא one to many relation), גם זו סיבה להעדיף את הגישה השניה.
במקרה אחר שבו כל מוצר הוא ייחודי ואין אפשרות של שני משתמשים עם אותו מוצר (מה שנקרא one to one relation), השיטה הראשונה עדיפה, ואולי אפילו לא נצטרך לשמור document של המוצרים בנפרד אלא הם יהיו רק תחת המשתמש שרכש אותם. אבל שוב, זה תלוי בצרכים של המערכת שלנו. אם יש לנו צורך להריץ שאילתות על המוצרים בנפרד מהלקוחות יכול להיות שגם במקרה הזה נעדיף את השיטה של ה-reference ונשמור כל מוצר בנפרד.
מקרה שלישי אפשרי הוא many to many relation. זה מקרה שבו יכול להיות ריבוי של קשרים לשני הכיוונים. למשל מערכת קורסים של סטודנטים. כל סטודנט לומד כמה קורסים, ומהכיוון השני לכל קורס יש כמה סטודנטים. גם במקרה הזה בד"כ נעדיף להשתמש ב-reference כדי לקשר בין סטודנטים לקורסים. אבל, יכול להיות לנו מקרים של many to many או one to many שדווקא שיטת ה-nested document תתאים יותר. זה תלוי כמובן בשימוש שנעשה במערכת שלנו, ולכן צריך לבחון כל מקרה לגופו ולהתאים לו את השיטה הנכונה עבורו.
כאשר משתמשים ב-reference כדי להתייחס בקולקשיין אחד למידע מקולקשיין אחר, נצטרך שני צעדים כדי לקבל את המידע. בצעד הראשון ניקח את הנתון ששמרנו אצלנו כ-reference. ולאחר מכן נשתמש ב-reference כדי לקבל את המידע מהקולקשיין שבו הוא נמצא.
ישנה דרך לעשות זאת בצעד אחד וזה ע"י שימוש ב-aggregate. עוד לא למדנו על aggregate וזה נושא רחב שנלמד עליו בהמשך (פרק 9) אבל רק נראה איך בעזרתו נוכל לקבל את המידע שיש לנו reference אליו בצעד אחד בלבד:
db.users.aggregate([
{
$lookup: {
from: "products", localField: "products", foreignField: "_id", as: "productDoc"
}
}
])הפקודה הזו תיקח את ה-reference ששמרנו בקולקשיין users בשדה products ותשתמש בו כדי להביא את המסמכים של המוצרים מקולקשיין שנקרא products כאשר ה-reference מייצג את שדה ה-id_ של המוצר. את המסמכים האלו היא תכניס לשדה שנקרא productDoc.
בדיקת סוג הנתונים - validation
הדרך הפשוטה להכניס validation על קולקשיין היא ביצירת הקולקשיין. עד עכשיו השתמשנו ב-lazy creation של קולקשיין. הכוונה היא, שלא יצרנו במפורש את הקולקשיין אלא ברגע שהתחלנו לכתוב לתוך קולקשיין מסוים אוטומטית הוא נוצר.
אבל יש אפשרות גם ליצור קולקשיין באופן מפורש ע"י createCollection, ואז ניתן גם לקנפג את הקולקשיין.
db.createCollection("products", { validator: { $jsonSchema: { bsonType: 'object', required: ['name', 'price', 'details'], properties: { name: { bsonType: "string", description: "must be a string and it is required" }, price: { bsonType: "number", description: "must be a number and it is required" }, details: { bsonType: "array", required: ['weight', 'length'], items: { weight: { bsonType: number, description: "must be a number and it is required" }, length: { bsonType: number, description: "must be a number and it is required" }, } }, } } } });
- בפרמטר הראשון אנחנו קובעים את שם הקולקשיין.
- בפרמטר השני אנחנו מגדירים את ה-validator.
- אנחנו משתמשים בפקודה jsonSchema$ כדי להגדיר את ה-schema של הקולקשיין.
- ע"י bsonType אנחנו מגדירים שכל מסמך שמוכנס לקולקשיין צריך להיות אובייקט וואלידי (valid document).
- ע"י required אנחנו קובעים את השדות שחובה שיהיו בכל אובייקט בקולקשיין הזה.
- ע"י properties אנחנו כבר נכנסים יותר לפרטים ומגדירים על כל שדה מה הסוג שלו. בנוסף אנחנו יכולים גם להוסיף description שמתאר במילים שלנו את הדרישות מהשדה הזה.
- במקרה של שדה מסוג array, אנחנו יכולים גם להיכנס לעומק ולהגדיר כל איבר במערך שלו מאיזה סוג הוא ועוד פרטים.
- אם עכשיו ננסה להכניס מסמך לקולקשיין הזה שלא יענה על כל הדרישות של ה-validation - המסמך לא יוכנס לקולקשיין ואנחנו נקבל שגיאה של "Document failed validation".
שינוי ה-vlaidation
במקרה שהגדרנו validation ולאחר זמן אנחנו רוצים לשנות את ה-validation נוכל להשתמש בפקודת runCommand שמריצה פקודות על ה-DB. הפקודה שנרצה להשתמש בה היא collMod (קיצור של collection modifier). נשלח את שם הקולקשיין ואת ה-validation החדש שבו נרצה להשתמש.
למשל אם נרצה שבמקרה שמסמך לא תואם ל-validator הוא לא ידחה ובכל זאת יכנס ל-DB נעשה זאת כך:
db.runCommand({collMod: "products",
validator: {
$jsonSchema: {
bsonType: 'object',
required: ['name', 'price', 'details'],
properties: {
name: {
bsonType: "string",
description: "must be a string and it is required"
},
price: {
bsonType: "number",
description: "must be a number and it is required"
},
details: {
bsonType: "array",
required: ['weight', 'length'],
items: {
weight: {
bsonType: number,
description: "must be a number and it is required"
},
length: {
bsonType: number,
description: "must be a number and it is required"
},
}
},
}
},
validationAction: 'warn'
});השורה האחרונה שבה כתבנו validationAction קובעת האם כל מסמכים שלא תואמים ל-validator ידחו או לא. הדיפולט הוא error, מה שאומר שכל פעולות ה-insert וה-update שלא יתאימו ל-validator יקבלו שגיאה וידחו. אנחנו במקרה הזה קבענו את זה כ-warn, מה שאומר שנקבל הודעת אזהרה לתוך ה-log file של ה-DB אבל הפעולה לא תידחה והמסמך באמת יכתב ל-DB.
פרק 3: אפשרויות קונפיגורציה של mongoDB
כמו שהוסבר בפרק 1 הכי קל להריץ את מונגו דרך ה-services של windows. כאן נביא עוד כמה אפשרויות של הרצה וקונפיגורציה.
כדי להריץ את mongo ב-windows לאחר שהורדנו אותו נשתמש בפקודה:
mongod
אצלי במחשב הקובץ הזה נמצא במיקום הבא:
C:\Program Files\MongoDB\Server\6.0\bin
כשמריצים את mongod ניתן לקנפג אותו. נדבר עכשיו על חלק קטן מהאפשרויות.
הפורט הדיפולטיבי של מונגו הוא 27017. כדי להשתמש בפורט אחר נשתמש באפשרות הבאה:
mongod --port 1234
כדי לראות את כל האפשרויות נריץ:
mongod --help
כדי להגדיר את ה-path שבו ישמר המידע (בדיפולט המידע ישמר ב-root folder שלי) נשתמש ב-dbpath וכדי להגדיר את המקום שבו ישמרו הלוגים נשתמש ב-logpath.
mongod --dbpath \path\to\my\db\folder --logpath \path\to\my\log\folder\log.log
שימו לב שעבור הלוגים יש צורך לתת שם של קובץ בסוף ולא רק שם של ספריה (אם הקובץ לא קיים הוא יווצר אוטומטית).
כשנריץ את זה, נראה הרבה פחות הדפסה למסך. וזה כיון שכל ההדפסות נכתבות עכשיו לתוך קובץ הלוג.
במקרה שיש לנו בעיות התחברות ל-DB ואנחנו רואים כל מני errors ו-warnings כדאי לנסות להשתמש באפשרות של repair.
mongod --repair
וזה לפעמים מצליח לתקן את הבעיות.
כדי שכל DB ישמר בתיקייה שונה נוכל להשתמש באפשרות:
mongod --directoryperdb
וכך לכל DB תהיה תיקיה משלו בשם של ה-DB.
ניתן להריץ את מונגו כ-process נפרד. בלינוקס ו-mac נשתמש בפקודת fork--.
כשמשתמשים בפקודה הזו חייבים להוסיף גם logpath כיון שהאופציה הדיפולטיבית להדפסה על המסך לא אפשרית כי מונגו רץ על תהליך אחר ולא תופס לנו את המסך של ה-shell.
mongod --fork --logpath \path\to\my\log\folder\log.log
ב-windows נצטרך לבחור במהלך ההתקנה את האפשרות של install as a serivce. נריץ את ה-cmd כמנהלים (לחיצה ימנית על command prompt ואז בחירה ב-run as administrator) ואז נכתוב:
net start MongoDB
כדי לסגור את התהליך של מונגו שרץ ברקע נצטרך להתחבר למונגו דרך ה-shell שלו ואז:
> use admin
> db.shutdownServer()
הדרך הזו תעבור גם ב-windows וגם בלינוקס.
אפשרות נוספת ב-windows היא לכתוב:
net stop MongoDB
פרק 4: פעולות Create
עד כה למדנו על פקודות insertOne, insertMany.
פקודה נוספת שניתן להשתמש בה היא פקודת insert. הפקודה הזו מאפשרת להכניס גם אובייקט אחד וגם מספר אובייקטים. והיא עושה פעולה דומה לפקודות הקודמות. עם זאת, הפקודה הזו ישנה יותר וכבר מוגדרת כ-deprecated ולכן מומלץ להימנע ממנה.
בכל זאת ניראה דוגמה קצרה של שימוש בה:
persons> db.contacts.insert({name: "Shlomo", age: 40})
DeprecationWarning: Collection.insert() is deprecated. Use insertOne, insertMany, or bulkWrite.
{
acknowledged: true,
insertedIds: { '0': ObjectId("64588e58fc3a938b9c3a69ba") }
}
persons> db.contacts.insert([{name: "Hila", age: 39}, {name: "Michal", age: 42}])
{
acknowledged: true,
insertedIds: {
'0': ObjectId("64588eb8fc3a938b9c3a69bb"),
'1': ObjectId("64588eb8fc3a938b9c3a69bc")
}
}שימו לב ל-DeprecationWarning.
Ordered inserts
אחד מעקרונות הפעולה של MongoDB נקרא ordered inserts. ההסבר די פשוט. כש-MongoDB מקבל פקודה להכנסה של נתונים הוא יכניס אותם אחד אחד לפי הסדר שהוא קיבל אותם. ואם אחד יכשל מכל סיבה שהיא, הוא יעצור ולא ימשיך לנתונים הבאים אבל הוא גם לא יוציא את הנתונים הקודמים שהוא כבר הצליח להכניס, אפילו אם הכל נשלח אליו בפקודה אחת.
דוגמה קצרה תסביר את זה בקלות. כבר הזכרנו ש-MongoDB מוסיף לכל אובייקט שדה של id_ בצורה אוטומטית. השדה הזה חייב להיות ייחודי לכל אובייקט ב-collection. וגם הזכרנו שניתן להכניס את השדה הזה בצורה מפורשת עם איזה ערך שאנו רוצים. למשל:
persons> db.persons.insertMany([{_id: 1, name: "Rafael"}, {_id: 2, name:"Noam"}])
{ acknowledged: true, insertedIds: { '0': 1, '1': 2 } }עכשיו ננסה להכניס עוד נתונים כשלאחד מהם ניתן id_ שכבר קיים ב-collection:
persons> db.persons.insertMany([{_id: 3, name: "Tal"},{_id: 2, name:"Hila"}, {_id: 4, name:"Rachel"}])
Uncaught:
MongoBulkWriteError: E11000 duplicate key error collection: persons.persons index: _id_ dup key: { _id: 2 }
Result: BulkWriteResult {
insertedCount: 1,
matchedCount: 0,
modifiedCount: 0,
deletedCount: 0,
upsertedCount: 0,
upsertedIds: {},
insertedIds: { '0': 3, '1': 2, '2': 4 }
}
Write Errors: [
WriteError {
err: {
index: 1,
code: 11000,
errmsg: 'E11000 duplicate key error collection: persons.persons index: _id_ dup key: { _id: 2 }', errInfo: undefined, op: { _id: 2, name: 'Hila' } } } ]
קיבלנו שגיאה של duplicate key, כיון שעבור Hila השתמשנו ב-id_ שכבר קיים ב-collection.
נבדוק מה קיים עכשיו ב-collection:
persons> db.persons.find()
[
{ _id: 1, name: 'Rafael' },
{ _id: 2, name: 'Noam' },
{ _id: 3, name: 'Tal' }
]כפי שרואים Tal, שהוכנס בפקודה השניה שבה קיבלנו את השגיאה, קיים ב-collection. וזה מכיון שהשגיאה היתה רק בנתון הבא (Hila) שניסינו להכניס. ולפי עיקרון ordered inserts כל אחד נכנס בנפרד ולכן Tal הצליח להיכנס.
לעומת זאת, הנתון של Rachel לא הוכנס למרות שלא היתה בו שום בעיה, וזה מכיון שהבעיה שהיתה עם Hila עצרה את המשך הפעילות.
יש מקרים שבהם אנחנו צריכים לשנות את ההתנהגות הזו ולגרום ל-MongoDB להכניס את כל הנתונים שהוא יכול להכניס ולא לעצור בגלל נתון שיש בו בעיה. כדי לעשות את זה נכתוב את הפקודה הבאה:
persons> db.persons.insertMany([
{_id: 3, name: "Tal"},{_id: 2, name:"Hila"}, {_id: 4, name:"Rachel"}],
{ordered: false})
Uncaught:
MongoBulkWriteError: E11000 duplicate key error collection: persons.persons index: _id_ dup key: { _id: 3 }
Result: BulkWriteResult {
insertedCount: 1,
matchedCount: 0,
modifiedCount: 0,
deletedCount: 0,
upsertedCount: 0,
upsertedIds: {},
insertedIds: { '0': 3, '1': 2, '2': 4 }
}
Write Errors: [
WriteError {
err: {
index: 0,
code: 11000,
errmsg: 'E11000 duplicate key error collection: persons.persons index: _id_ dup key: { _id: 3 }', errInfo: undefined, op: { _id: 3, name: 'Tal' } } }, WriteError { err: { index: 1, code: 11000, errmsg: 'E11000 duplicate key error collection: persons.persons
index: _id_ dup key: { _id: 2 }', errInfo: undefined, op: { _id: 2, name: 'Hila' } } } ]
בסוף הפקודה הוספנו {ordered: false}. ההוספה הזו אומרת ל-MongoDB לא לפעול לפי הסדר ולעצור, אלא להמשיך ולהכניס את כל הנתונים שהוא יכול. ולכן במקרה הזה למרות שאת שני הנתונים הראשונים הוא לא יכול להכניס כי ה-id_ שלהם כבר קיים ב-collection, הוא בכל זאת מכניס את הנתון השלישי של Rachel.
נבדוק מה יש לנו ב-collection:
persons> db.persons.find()
[
{ _id: 1, name: 'Rafael' },
{ _id: 2, name: 'Noam' },
{ _id: 3, name: 'Tal' },
{ _id: 4, name: 'Rachel' }
]האפשרות הזו יכולה לעזור לנו במקרים שבהם אין לנו שליטה מלאה על מה מנסים להכניס ל-DB ואנו לא רוצים להכשיל את כל הנתונים בגלל שחלק מהנתונים כבר קיימים.
ה-Storage Engine ו-WriteConcern
ב-MongoDB יש רכיב שנקרא Storage Engine. הרכיב הזה אחראי על הכתיבה של הנתונים לזיכרון וכן על ניהול הזיכרון. כדי לעבוד מהר, ה-Storage Engine שומר את הנתונים בזיכרון ורק בהמשך כותב אותם לדיסק.
יש לנו אפשרות לקנפג את צורת הכתיבה כך שתהיה יותר מהירה או לחילופין יותר בטוחה (הבטיחות בכתיבה באה על חשבון המהירות).
נסביר את האפשרויות תוך כדי דוגמאות.
persons> db.persons.insertOne({name: 'Yael', age: 33}, {writeConcern: {w: 1}})
{
acknowledged: true,
insertedId: ObjectId("6459dedbfc3a938b9c3a69bd")
}בדוגמא הזו הוספנו אובייקט שנקרא writeConcern ובתוכו שדה של w (קיצור של write) עם ערך 1. זה אומר שאנחנו רוצים לקבל אישור (acknowledgement) מאינסטנס אחד. MongoDB יכול לרוץ על מספר מכונות. בדוגמה הזו ביקשנו לקבל אישור לפחות ממכונה אחת שהמידע נכתב. אפשר להעלות את ערך ה-w כדי לקבל אישור מיותר מכונות. נשתמש בזה במקרים שהמידע מאוד חשוב לנו ואנחנו רוצים לדעת שהוא נכתב על כמה שרתים. בכל מקרה הדיפולט הוא 1.
במקרים אחרים בהם מהירות הכתיבה חשובה לנו יותר מהבטיחות בכתיבה נוכל לכתוב:
persons> db.persons.insertOne({name: 'Yehuda', age: 21}, {writeConcern: {w: 0}})
{
acknowledged: false,
insertedId: ObjectId("6459dff9fc3a938b9c3a69be")
}בפקודה הזו ביקשנו שהכתיבה לא תחכה לאישור משום מכונה. ולכן רואים שקיבלנו:
acknowledged: false
במקרה הזה קיבלנו בחזרה את ה-insertedId אבל יכול להיות שגם אותו לא נקבל כי עוד לפני שהוא נכתב וקיבל id התשובה כבר חזרה אלינו.
למשל, אם אנחנו שומרים נתונים כלליים על המערכת שלנו ולא אכפת לנו אם פה ושם חלק מהנתונים לא יכתבו אבל יותר חשוב לנו שפעולות הכתיבה לא יגרמו לאיטיות במערכת - נשתמש באפשרות הזו.
עכשיו נראה אפשרות נוספת:
persons> db.persons.insertOne({name: 'Sami', age: 11}, {writeConcern: {w: 1, j: false}}){
acknowledged: true,
insertedId: ObjectId("6459e1b7fc3a938b9c3a69c7")
}הפעם השתמשנו באפשרות j (קיצור של journal). ה-journal הוא קובץ שמנוהל ע"י ה-Storage Engine שבו הוא כותב מה עוד הוא צריך לעשות. דברים שהתחילו אבל עוד לא הסתיימו. למשל נתונים שנכתבו לזיכרון אבל עדיין לא נכתבו לדיסק שם יהיה כתוב שצריך לכתוב אותם אם נשתמש ב-j: true.
כמובן שגם אם לא נשתמש ב-journal הנתונים יכתבו לדיסק, אבל היתרון של ה-journal הוא במקרה שהמערכת קרסה לפני שהנתונים נכתבו לדיסק אבל הם כבר נכתבו ל-journal. במקרה כזה, כשהמערכת תעלה מחדש היא תשתמש ב-journal כדי לדעת מה היא צריכה לעשות. זו בעצם שכבת ביטחון נוספת לנתונים שלנו.
נשאלת השאלה, אם כבר כתבנו את הנתונים ל-journal למה לא כתבנו את זה ישירות ל-DB?
והתשובה היא, שכתיבה ל-journal קצרה משמעותית מכתיבה ל-DB. ב-journal זה כתיבה פשוטה של שורה לתוך קובץ. לעומת זאת בכתיבה ל-DB צריך למצוא את המקום הנכון וליצור id ולפעמים גם ליצור אינדקס ועוד פעולות אחרות שיכולות להיות ב-DB ודורשות יותר זמן. ולכן כתיבה ל-journal עוזרת לנו, כי היא כותבת יותר מהר את מה שצריך לעשות בהמשך ואז במקרה של קריסה יש סיכוי גבוה יותר שהמידע נשמר ב-journal מאשר הסיכוי שהוא כבר נכתב ל-DB.
כמובן ששימוש ב-journal גורם בסופו של דבר למערכת להיות קצת יותר איטית כי נכנס פה עוד דרישה מהמערכת. אבל זה מעלה לנו את הביטחון של כתיבת הנתונים שלנו.
כאשר משתמשים ב-journal אנחנו מקבלים acknowledgement רק לאחר שהנתונים נכתבו לזיכרון וגם ל-journal וזה מעלה לנו את הביטחון בכתיבת הנתונים.
השימוב ב-journal נראה כך:
persons> db.persons.insertOne({name: 'Dudu', age: 43}, {writeConcern: {w: 1, j: true}})
{
acknowledged: true,
insertedId: ObjectId("6459e9effc3a938b9c3a69c8")
}אפשרות שלישית שיש לנו ב-writeConcern נקראת wtimeout. האפשרות הזו מגדירה כמה זמן אנחנו נותנים למערכת שלנו לדווח על acknowledgement לפני ביטול הפעולה. למשל אם יש לנו בעיות ברשת אנחנו נרצה לבטל את פעולת הכתיבה לאחר זמן מסוים כי אנחנו מבינים שכרגע הפעולה בכל מקרה לא תצליח בגלל בעיות ברשת. מצד שני אם נשתמש בערך קטן מדי, יכול להיות שהפעולה תתבטל למרות שהיתה יכולה להצליח אם היינו מחכים קצת יותר זמן.
persons> db.persons.insertOne({name: 'Dudu', age: 43}, {writeConcern: {w: 1, j: true, wtimeout: 200}})
{
acknowledged: true,
insertedId: ObjectId("6459ec9cfc3a938b9c3a69c9")
}במקרה הזה נתנו לפעולת הכתיבה 200 msec.
persons> db.persons.insertOne({name: 'David', age: 43}, {writeConcern: {w: 1, j: true, wtimeout: 1}})
{
acknowledged: true,
insertedId: ObjectId("6459eca0fc3a938b9c3a69ca")
}וכאן נתנו רק 1 msec.
את הדוגמאות במדריך הזה בדקתי לוקאלית ולכן אפילו 1 מצליח אבל במקרה של עבודה מול שרת מרוחק הפעולה הזו ככל הנראה תיכשל ולכן צריך לתת ערך נכון לפי סוג המערכת אם משתמשים באפשרות הזו.
אם לא נשתמש ב-wtimeout אז פעולת הכתיבה תימשך עד שתצליח ולכן אם יש בעיות במערכת היא יכולה להימשך לנצח ולתקוע את המערכת. אגב, אם נשתמש בערך של 0 המשמעות היא שהכתיבה לא תהיה מוגבלת בזמן.
אטומיות - Atomicity
אחד העקרונות של MongoDB הוא אטומיות ברמת ה-document.
נסביר את העיקרון. לפעמים קורה שפעולת כתיבה ל-DB נכשלת. יכול להיות שהיא תיכשל ממש באמצע כתיבת נתונים לדיסק. במקרה כזה יכול היה להיות שכמה שדות מה-document נכתבו ושאר השדות לא.
מה ש-MongoDB מבטיח לנו זה שברמת ה-document יש לנו אטומיות. במילים אחרות, מובטח לנו שאם הפעולה הצליחה כל ה-document נכתב לדיסק ואם היא נכשלה אז כל ה-document לא נכתב לדיסק. ואין מצב שרק חלק מה-document נכתב לדיסק וחלק לא.
העיקרון הזה נכון לכל פקודות הכתיבה. אבל, כמו שראינו לעיל, בפקודת writeMany יכול להיות שלא כל ה-documents (ברבים) יכתבו לדיסק, כי אולי באחד מהם יש שגיאה, כמו שימוש ב-id_ שכבר קיים. אבל לא יכול להיות שחלק מ-document יכתב וחלק לא. לכן זה נקרא אטומיות ברמת ה-document.
פרק 5: פעולות Read
כדי להתעמק באפשרויות קריאת הנתונים, ניצור DB משמעותי כדי שיהיה עם מה לעבוד.
נוריד את הקובץ tv-shows.json מכאן:
https://github.com/mganitombalak/training/blob/master/tv-shows.json
הקובץ הזה כולל הרבה תוכניות טלוויזיה עם מידע עליהם.
כדי לטעון את הנתונים נשתמש בכלי שנקרא mongoimport.
ייבוא נתונים
ניתן לייבא נתונים לתוך MongoDB ע"י כלי שנקרא mongoimport. את הכלי הזה צריך להתקין בנפרד וכיום הוא חלק מה-MongoDB Database Tools package. הכי טוב לחפש בגוגל איך להתקין אותו. נכון לכתיבת שורות אלו ניתן לקבל על כך מידע כאן.
לא ניכנס לעומק רק נראה דוגמה פשוטה:
C:\Users\rafael>mongoimport C:\Users\rafael\Downloads\tv-shows.json -d tv
-c shows --jsonArray
2023-05-12T10:42:50.354+0300 connected to: mongodb://localhost/
2023-05-12T10:42:50.393+0300 240 document(s) imported successfully. 0 document(s) failed to import.בדוגמה הזו אנחנו מייבאים את הנתונים שיש בקובץ tv-shows.json (צריך לתת לו את ה-path הנכון לפי המיקום שלו במערכת).
בעזרת d- אנחנו מציינים שהנתונים יכנסו ל-DB שנקרא tv.
בעזרת c- אנחנו מציינים שהנתונים יכנסו ל-collection שנקרא shows.
בעזרת jsonArray-- אנחנו גורמים לפעולת הייבוא להתייחס לנתונים כמערך של נתונים כדי שלא יקח את הכל כ-document אחד.
עכשיו יש לנו DB בשם tv שיש בו collection שנקרא shows עם 240 documents.
סינון נתונים
לעיל, כשהסברנו על find הסברנו קצת על אפשרויות ה-filter שיש לנו בקריאת נתונים. עכשיו נעמיק בזה ונראה אפשרויות נוספות.
בנתונים של הסרטים שלנו, לכל סרט יש שדה שנקרא runtime עם ערך מספרי.
כדי לקבל את כל הסרטים שיש להם runtime ששווה ל-60 נכתוב:
tv> db.shows.find({runtime: 60})
לחילופין אפשר גם להשתמש באופרטור:
tv> db.shows.find({runtime: {$eq:60}})
שני הפקודות האלה זהות.
אופרטורים של השוואה (comparison operators)
אם נרצה את כל הסרטים שיש להם runtime שונה מ-60 נכתוב:
tv> db.shows.find({runtime: {$ne:60}})
וכדי לקבל את כל הסרטים עם runtime קטן מ-60 נכתוב:
tv> db.shows.find({runtime: {$lt: 60}})
ואם אנחנו רוצים את כל הסרטים עם runtime קטן או שווה ל-60 נכתוב:
tv> db.shows.find({runtime: {$lte: 60}})
ואם רוצים להיפך, את כל הסרטים עם runtime גדול או שווה ל-60 נכתוב:
tv> db.shows.find({runtime: {$gte: 60}})
אפשר גם לציין ערכים מסוימים שרק אותם אנחנו רוצים למשל:
tv> db.shows.find({runtime: {$in: [40, 25]}})
הפקודה הזו תחזיר לי את כל התוכניות שה-runtime שלהם הוא 40 או 25. במקרה שלנו יש רק 2 תוכניות כאלו.
ואפשר להשתמש בפקודה ההפוכה כדי לבקש שיחזיר לנו את כל התוכניות שאין להם ערכים מסוימים:
tv> db.shows.find({runtime: {$nin: [18, 44]}})
הפקודה הזו תחזיר לי את כל התוכניות שה-runtime שלהם הוא לא 18 ולא 44.
שדות פנימיים
ניתן גם לסנן ע"י שדות פנימיים. למשל בתוך השדה rating יש שדה average וכדי לסנן לפי הערך של השדה הפנימי נוכל לכתוב:
tv> db.shows.find({"rating.average": {$gt: 7}})
שימו לב שכדי להשתמש בצורה הזו חייבים לשים את שם השדה בגרשיים.
מערכים
בנתונים שלנו יש מערך בשם genres ויש סרטים שיש להם במערך הזה מספר ערכים, למשל:
genres: [ 'Drama', 'Action', 'Crime' ]
אם נעשה חיפוש בצורה הבאה:
tv> db.shows.find({genres: "Drama"})
נקבל בחזרה את כל הנתונים שיש להם במערך genres את הערך Drama גם אם הוא לא הערך היחיד שיש במערך.
אם אנחנו מעוניינים לקבל חזרה רק את הנתונים שיש במערך genres שלהם את הערך Drama בלבד, נוסיף סוגריים מרובעים מסביב ל-Drama כדי לסמן שאנחנו רוצים מערך בדיוק כזה:
tv> db.shows.find({genres: ["Drama"]})
אופרטורים לוגיים - logical operators
or
כדי למצוא מסמכים לפי מספר תנאים ניתן להשתמש ב-or.
נבדוק כמה סרטים עם דירוג נמוך יותר מ-5 יש לנו:
tv> db.shows.find({ "rating.average": { $lt: 5 } }).count()
2
נבדוק כמה סרטים עם דירוג גבוה יותר מ-9 יש לנו:
tv> db.shows.find({ "rating.average": { $gt: 9 } }).count()
7
עכשיו נשתמש ב-or כדי לבדוק כמה סרטים יש לנו עם דירוג נמוך יותר מ-5 או גבוה יותר מ-9:
tv> db.shows.find({$or: [{"rating.average": {$lt: 5}}, {"rating.average": {$gt: 9}}]}).count()
9
שימו לב לצורת הכתיבה, מתחילים עם האופרטור, ואז מכניסים למערך את כל התנאים שאנחנו רוצים לבדוק, כל אחד בתוך סוגריים מסולסלים משלו.
nor
האופרטור ההופכי של or הוא nor. הוא ייתן לנו את כל המסמכים שלא מקיימים אף אחד מהתנאים שנכניס למערך.
נבדוק תחילה כמה מסמכים יש לנו ב-DB:
tv> db.shows.find().count()
240
יש לנו 240 מסמכים, וראינו בתנאי של ה-or שקיבלנו חזרה 9 מסמכים. לכן עם התנאי של ה-nor נצפה לקבל 231 מסמכים:
tv> db.shows.find({$nor: [{"rating.average": {$lt: 5}}, {"rating.average": {$gt: 9}}]}).count()
231
and
באותה צורה כמו שהשתמשנו באופרטורים הקודמים נוכל להשתמש גם ב-and כדי למצוא מסמכים שעונים על מספר תנאים. למשל סרטים עם דירוג מסוים ועם ז'אנר מסוים:
tv> db.shows.find({$and: [{"rating.average": {$gt: 8}}, {"genres": "Crime"}]}).count()
35
בשאילתא הזו מצאנו כמה מסמכים יש עם דירוג מעל 8 ועם ז'אנר של פשע.
ניתן גם לכתוב שאילתות של and בצורה מקוצרת:
tv> db.shows.find({"rating.average": {$gt: 8}, "genres": "Crime"}).count()
35
פשוט מכניסים לתוך החלק של הפילטר את כל התנאים שאנחנו רוצים למצוא.
אם כן, נשאלת השאלה למה צריך את האופרטור and?
התשובה היא, למקרה שאנחנו רוצים כמה תנאים על אותו שדה. למשל אנחנו רוצים סרטים שיש להם ז'אנר גם של Crime וגם של Drama:
tv> db.shows.find({"genres": "Drama", "genres": "Crime"}).count()
53
זה עובד טוב ב-mongo shell אבל בחלק מהדרייברים זה לא יעבוד. למשל ב-JavaScript נקבל שגיאה כיון שאסור לכתוב אובייקט שיש לו שני שדות עם אותו שם (במקרה שלנו כתבנו שני שדות של genres).
אבל זה לא הכל. השאילתא האחרונה שכתבתי בכלל לא מחזירה לנו את מה שאנחנו מצפים. נראה את זה כשנשווה את מה שקיבלנו למה שנקבל בשאילתא הבאה כשנכתוב את אותו תנאי אבל עם and:
tv> db.shows.find({$and: [{"genres": "Drama"}, {"genres": "Crime"}]}).count()
47
נראה מוזר. הפעם קיבלנו רק 47 סרטים.
הסיבה לכך היא, שגם אם לא קיבלנו שגיאה ב-mongo shell עבור שימוש באובייקט בעל שני שדות עם אותו שם, מה שבפועל הוא עשה זה לדרוס את השדה הראשון עם הערך של השדה השני. במילים אחרות זה מה שהוא חיפש לנו בפועל:
tv> db.shows.find({"genres": "Crime"}).count()
53
ולכן, חשוב לזכור שאם משתמשים באותו שדה יותר מפעם אחת, חובה להשתמש ב-and. אחרת לא נקבל מה שאנחנו באמת רוצים.
not
האופרטור not מחזיר לנו את ההפך ממה שהשאילתא שלנו מחזירה.
למשל, כדי למצוא כמה סרטים שהם לא בז'אנר של פשע יש לנו נכתוב:
tv> db.shows.find({genres: {$not: {$eq: "Crime"}}}).count()
187
אפשר כמובן להשתמש באופרטור ne שדיברנו עליו לעיל. הוא עושה את אותו הדבר. וכן ניתן להשתמש ב-nor בשביל תנאי של not or. אבל, למקרים שאין לנו אופרטור מיוחד מקוצר, נשתמש ב-not.
Element operators
ישנם שני elment operators.
הראשון זה exists. שבודק האם קיים שדה מסוים.
למשל הפקודה הבאה:
persons> db.users.find({height: {$exists: true}})
תחזיר רק מסמכים שיש להם שדה שנקרא height. אפילו אם הערך שלו null.
אם אנחנו רוצים לוודא שמסמכים שיש להם שדה height ששווה ל-null לא חוזרים נכתוב:
persons> db.users.find({height: {$exists: true, $ne: null}})
כדי לקבל את כל המסמכים שאין להם שדה height נשתמש כמובן ב-false:
persons> db.users.find({height: {$exists: false}})
האופרטור השני נקרא type והוא בודק את סוג הנתון.
למשל, הפקודה הבאה:
persons> db.users.find({height: {$type: "number"}})
תחזיר לי מסמכים שיש להם שדה height מסוג number.
ואפשר גם לחפש לפי כמה סוגים:
persons> db.users.find({height: {$type: ["number", "string"]}})
את כל ה-types הקיימים ניתן לראות כאן https://www.mongodb.com/docs/manual/reference/bson-types/.
Evaluation operators
regex
מאפשר לנו לחפש תבניות בטקסט.
למשל ב-collection של ה-shows יש שדה שנקרא summary ובו יש תיאור לגבי אותו סרט. אז אם למשל אנחנו רוצים למצוא כל סרט שיש בתיאור שלו את המילה music, נכתוב:
tv> db.shows.find({summary: {$regex: /music/}}).count()
5
אכן יש 5 סרטים כאלה.
שימו לב שאת התבנית צריך לכתוב בין שני קווים נטויים.
expr
האופרטור הזה מאפשר לנו השוואה בין שדות.
למשל ב-collection של ה-shows יש שדה של runtime ושדה של weight. אם אנחנו רוצים למצוא את כל המסמכים שבהם ה-runtime גדול מה-weight נכתוב:
tv> db.shows.find({$expr: {$gt: ["$runtime", "$weight"]}}).count()
41
ואם נרצה למצוא את ההפך נכתוב:
tv> db.shows.find({$expr: {$lt: ["$runtime", "$weight"]}}).count()
199
עכשיו נראה מקרה מסובך יותר.
אם נעיין בנתונים שלנו, נראה שב-41 תוצאות שבהם runtime גדול מ-weight יש כמה שבהם ה-weight שווה לאפס. זה כנראה מידע לא נכון שפשוט היה חסר. ולכן נגיד שבמקרה כזה אני רוצה להחזיר את כל המסמכים שבהם runtime גדול מ-weight אבל אם weight שווה לאפס אני רוצה להוסיף לו 30 ככה שיהיה לו ערך כלשהו שאולי הגיוני (סתם המצאתי מקרה).
במקרה הזה השאילתא תהיה יותר מורכבת, בואו נראה:
tv> db.shows.find({$expr: {$gt: ["$runtime",
{$cond: {if: {$eq: ["$weight", 0]}, then: {$sum: ["$weight", 30]}, else: "$weight"}}]}}).count()
36
התחלת השאילתא דומה למה שכתבנו לעיל. אבל אז, במקום להשוות פשוט ל-weight הכנסנו תנאי (cond) שאומר שאם weight שווה לאפס אז תוסיף לו 30, אחרת תשאיר אותו כמו שהוא.
ואנחנו רואים במקרה הזה שהתשובה היא שרק 36 מסמכים עונים על השאילתא הזו.
תשאול מערכים
כשיש לנו נתונים במערך ואנחנו רוצים לחפש לפי שדה מסוים במערך, למשל במסמכים הבאים:
persons> db.users.find()
[
{
_id: ObjectId("647c3a194125808a1a7518f5"),
name: 'Dani',
friends: [ { name: 'Yosi', age: 25 }, { name: 'Didi', age: 26 } ]
},
{
_id: ObjectId("647c3a194125808a1a7518f6"),
name: 'Roni',
friends: [ { name: 'Yosi', age: 25 }, { name: 'Sasi', age: 27 } ]
}
]כדי למצוא את כל המשתמשים שיש להם חבר בשם Yosi נכתוב:
persons> db.users.find({'friends.name': 'Yosi'})
[
{
_id: ObjectId("647c3a194125808a1a7518f5"),
name: 'Dani',
friends: [ { name: 'Yosi', age: 25 }, { name: 'Didi', age: 26 } ]
},
{
_id: ObjectId("647c3a194125808a1a7518f6"),
name: 'Roni',
friends: [ { name: 'Yosi', age: 25 }, { name: 'Sasi', age: 27 } ]
}
]שימו לב שאם ננסה לחפש בצורה הבאה:
persons> db.users.find({'friends': {'name': 'Yosi'}})
לא נמצא שום דבר, כיון שאין לנו שום מסמך עם שדה בשם friends שיש בתוכו מסמך {'name': 'Yosi'}. במסמכים שלנו בשדה friends יש שדה נוסף בשם age ולכן לא נמצא דבר בצורה הזו. לעומת זאת בחיפוש בצורה הזו:
db.users.find({'friends.name': 'Yosi'})
מונגו יודע לחפש בתוך המערך האם יש בכלל מערך עם שדה friends שיש בו גם שדה name אפילו אם יש שדות נוספים.
size
אופרטור נוסף שעוזר לנו בעבודה עם מערכים הוא size. למשל, אם אנחנו רוצים לקבל את כל המשתמשים שיש להם 2 חברים, נכתוב את הדבר הבא:
persons> db.users.find({friends: {$size: 2}})
[
{
_id: ObjectId("647c3a194125808a1a7518f5"),
name: 'Dani',
friends: [ { name: 'Yosi', age: 25 }, { name: 'Didi', age: 26 } ]
},
{
_id: ObjectId("647c3a194125808a1a7518f6"),
name: 'Roni',
friends: [ { name: 'Yosi', age: 25 }, { name: 'Sasi', age: 27 } ]
}
]ב-size צריך לתת ערך מדויק. למשל, לא ניתן לבקש את כל המשתמשים שיש להם יותר מ-2 חברים או פחות מערך מסוים, אלא רק ערך מדויק.
all
כדי למצוא מסמכים שיש במערך שלהם ערכים מסוימים נוכל להשתמש ב-all. האופרטור הזה מחזיר את כל המסמכים שיש במערך שלהם את כל הערכים שביקשנו לבדוק.
לצורך הדוגמה נוסיף משתמש נוסף:
persons> db.users.insertOne({name: 'David', friends: [{ name: 'Sasi', age: 27 }, { name: 'Yosi', age: 25 }]})
{
acknowledged: true,
insertedId: ObjectId("647d6f8951915991c912a117")
}עכשיו יש לנו שלושה משתמשים:
persons> db.users.find()
[
{
_id: ObjectId("647c3a194125808a1a7518f5"),
name: 'Dani',
friends: [ { name: 'Yosi', age: 25 }, { name: 'Didi', age: 26 } ]
},
{
_id: ObjectId("647c3a194125808a1a7518f6"),
name: 'Roni',
friends: [ { name: 'Yosi', age: 25 }, { name: 'Sasi', age: 27 } ]
},
{
_id: ObjectId("647d6f8951915991c912a117"),
name: 'David',
friends: [ { name: 'Sasi', age: 27 }, { name: 'Yosi', age: 25 } ]
}
]אם ננסה לחפש משתמשים ש-Yosi ו-Sasi חברים שלהם בצורה הבאה:
persons> db.users.find({friends: [{name: 'Yosi', age: 25} , {name: 'Sasi', age: 27}]})
[
{
_id: ObjectId("647c3a194125808a1a7518f6"),
name: 'Roni',
friends: [ { name: 'Yosi', age: 25 }, { name: 'Sasi', age: 27 } ]
}
]נקבל רק את Roni למרות שאפשר לראות שגם ל-David יש את שני החברים האלה. הסיבה ש-David לא היה בתוצאות שמונגו החזיר היא שאצלו סדר החברים במערך שונה. כדי למצוא את כל המשתמשים שיש להם את שני החברים האלה בלי להתחשב בסדר שהם כתובים במערך נשתמש ב-all:
persons> db.users.find({friends: { $all: [{name: 'Yosi', age: 25}, {name: 'Sasi', age: 27}]}})
[
{
_id: ObjectId("647c3a194125808a1a7518f6"),
name: 'Roni',
friends: [ { name: 'Yosi', age: 25 }, { name: 'Sasi', age: 27 } ]
},
{
_id: ObjectId("647d6f8951915991c912a117"),
name: 'David',
friends: [ { name: 'Sasi', age: 27 }, { name: 'Yosi', age: 25 } ]
}
]האופרטור הזה מוודא שכל הערכים שביקשנו אכן נמצאים במערך ולא משנה מה הסדר שלהם.
elemMatch
נוסיף לכל משתמש שדה נוסף של kids ובו את שמות הילדים שלו והגיל של כל אחד:
persons> db.users.find()
[
{
_id: ObjectId("647c3a194125808a1a7518f5"),
name: 'Dani',
friends: [ { name: 'Yosi', age: 25 }, { name: 'Didi', age: 26 } ],
kids: [ { name: 'Yair', age: 2 }, { name: 'Ori', age: 3 } ]
},
{
_id: ObjectId("647c3a194125808a1a7518f6"),
name: 'Roni',
friends: [ { name: 'Yosi', age: 25 }, { name: 'Sasi', age: 27 } ],
kids: [ { name: 'Avigail', age: 3 }, { name: 'Orit', age: 4 } ]
},
{
_id: ObjectId("647d6f8951915991c912a117"),
name: 'David',
friends: [ { name: 'Sasi', age: 27 }, { name: 'Yosi', age: 25 } ],
kids: [ { name: 'Yair', age: 5 }, { name: 'Idan', age: 2 } ]
}
]ועכשיו ננסה למצוא את כל המשתמשים שיש להם ילד בשם Yair שבגיל 3 ומעלה:
persons> db.users.find({$and: [{"kids.name": "Yair"}, {"kids.age": {$gte: 3}}]})
[
{
_id: ObjectId("647c3a194125808a1a7518f5"),
name: 'Dani',
friends: [ { name: 'Yosi', age: 25 }, { name: 'Didi', age: 26 } ],
kids: [ { name: 'Yair', age: 2 }, { name: 'Ori', age: 3 } ]
},
{
_id: ObjectId("647d6f8951915991c912a117"),
name: 'David',
friends: [ { name: 'Sasi', age: 27 }, { name: 'Yosi', age: 25 } ],
kids: [ { name: 'Yair', age: 5 }, { name: 'Idan', age: 2 } ]
}
]ל-David באמת יש ילד בשם Yair שהגיל שלו מעל 3. אבל ל-Dani יש ילד בשם Yair בגיל 2, אז למה קיבלנו אותו?
התשובה היא, שהשאילתא שכתבנו מחפש משתמשים שיש להם ילד בשם Yair וגם ילד בגיל 3 ומעלה. אבל זה לא חייב להיות דווקא Yair. במקרה של Dani יש לו ילד בשם Ori שהוא בן 3 ולכן גם Dani חזר.
אם אנחנו רוצים לחפש משתמש שיש לו ילד בשם Yair בגיל 3 ומעלה נשתמש באופרטור elemMatch:
persons> db.users.find({kids: {$elemMatch: {name: "Yair", age: {$gte: 3}}}})
[
{
_id: ObjectId("647d6f8951915991c912a117"),
name: 'David',
friends: [ { name: 'Sasi', age: 27 }, { name: 'Yosi', age: 25 } ],
kids: [ { name: 'Yair', age: 5 }, { name: 'Idan', age: 2 } ]
}
]האופרטור הזה מחפש משתמשים שלהם יש אלמנט שעונה על כל הקריטריונים, ובמקרה שלנו זה רק David.
הבנת ה-cursor
כמו שהזכרנו בקצרה לעיל, פקודת find מחזירה לנו cursor ולא את המידע עצמו (בשונה מפקודת findOne שמחזירה את המידע עצמו). ה-cursor בא לשפר את היעילות. פקודת find יכולה להחזיר כמות גדולה של מסמכים שיצטרכו להישלח אלינו ויעמיסו את הרשת ואת הזיכרון. אז במקום לשלוח את כל המסמכים נשלח רק cursor שמצביע על המסמכים.
ה-cursor שומר את השאילתא שלנו ויכול ללכת במהירות ל-DB ולבקש כל פעם עוד ועוד מסמכים לפי הצורך שלנו. במקום לקבל את כל המסמכים בפעם אחת נקבל כל פעם batch (קבוצה) של מסמכים.
כשאנו שולחים שאילתא כזו ל-DB הוא כבר מתכונן לתת לנו תשובות המשך בצורה יעילה ע"י כך שהוא טוען לזיכרון של עצמו חלק מהמידע שחזר בשאילתא. לדוגמה, נבדוק על כמה מסמכים מצביע ה-cursor ע"י הפקודה count (נדגים זאת על ה-DB שנקרא tv שראינו כבר לעיל):
tv> db.shows.find().count()
240
במקרה הזה לא תרוץ שאילתא נוספת על ה-DB, אלא יוחזר לנו המידע הזה שכבר נשמר בזיכרון של ה-DB ומוכן לשליחה. זהו מנגנון יעיל, ולא בזבזני ששואל את אותה שאילתא שוב ושוב.
כשנריץ את פקודת find ב-mongosh נקבל כדיפולט 20 מסמכים כל פעם:
tv> db.shows.find()
(אני אחסוך מכם את הפלט הארוך). ואז בשורה האחרונה יהיה כתוב:
Type "it" for more
ואכן כל פעם שנכתוב it נקבל עוד 20 מסמכים. הוא בעצם משתמש ב-cursor שחזר כדי לבקשה עוד batch של מסמכים. בדוגמה שלנו יש 240 מסמכים לכן כל המסמכים יכנסו ב-12 batches ואם אחרי שיגמרו המסמכים אנסה שוב לכתוב it נקבל:
tv> it
no cursor
פקודה שימושית נוספת היא next שתיתן לנו כל פעם מסמך אחד:
tv> db.shows.find().next()
אבל אם נריץ את הפקודה הזו שוב - יווצר cursor חדש (כי שוב השתמשנו ב-find) ונקבל שוב את המסמך הראשון. לכן אנחנו צריכים לקרוא ל-find פעם אחת ואז לשמור את ה-cursor:
tv> const myCursor = db.shows.find()
ועליו להפעיל את פקודת next:
tv> myCursor.next()
כל פעם שנריץ את הפקודה הזו נקבל את המסמך הבא.
אפשר גם להריץ פונקציות על ה-cursor. למשל ב-javascript יש את פקודת forEach שעל ידה נוכל לרוץ על כל המסמכים אחד אחרי השני ולהפעיל על כל אחד פונקציה:
tv> myCursor.forEach(doc => {printjson(doc)})
בצורה הפשוטה הזו קיבלנו כל פעם מסמך אחד שעליו הפעלנו את הפונקציה printjson שזו פונקציה של mongosh, וכך הדפסנו את כל המסמכים.
אם עכשיו ננסה לקבל את המסמך הבא, נקבל שגיאה:
tv> myCursor.next()
MongoCursorExhaustedError: Cursor is exhausted
וזאת מכיון שכבר בפקודה הקודמת של forEach עברנו על כל המסמכים, אז אין עוד מסמכים ש-next יכול להביא.
אפשר גם לבדוק אם יש עוד מסמך עם הפונקציה הבאה:
tv> myCursor.hasNext()
false
מיון בעזרת ה-cursor
אפשר להשתמש בפונקציה sort כדי לקבל את תוצאות ה-cursor בצורה ממוינת:
tv> db.shows.find().sort({"rating.average": -1})
בדוגמה הזו נקבל את כל הסרטים ממויינים לפי השדה rating.average, כאשר המספר מינוס 1 מציין שאנחנו רוצים מיון בסדר יורד. ז"א שנקבל ראשון את הסרט עם ה-rating.average הגבוה ביותר, ואחרון את הסרט עם ה-rating.average הנמוך ביותר.
ניתן גם למיין על ידי יותר משדה אחד, כאשר השדה הראשון יהיה המיון העיקרי, והשדה השני יהיה המיון המשני עבור מסמכים עם אותו ערך במיון העיקרי וכן הלאה.
tv> db.shows.find().sort({"rating.average": -1, runtime: 1})
בדוגמה הזו נקבל את הסרטים לפי סדר יורד בערך ה-rating.average, וכאשר הערך ב-rating.average יהיה זהה בכמה מסמכים הם ימויינו בסדר עולה לפי ערך ה-runtime שלהם.
דילוג על תוצאות בעזרת skip
יכול להיות לנו מקרים שבהם יהיה צורך לדלג על תוצאות. למשל אם אנחנו רוצים להציג 10 תוצאות בכל עמוד, והמשתמש לחץ על עמוד 5, אנחנו צריכים להציג לו את תוצאות 41 עד 50 ולכן בעצם לדלג על ה-40 הראשונים.
אפשר לעשות זאת כך:
tv> db.shows.find().sort({"rating.average": -1}).skip(40)
בדוגמה הזו נקבל את התוצאות ממויינות בסדר יורד (הרייטינג הגבוה ראשון) אבל החל מתוצאה 41.
הגבלת כמות המסמכים בעזרת limit
אפשר להגביל את מספר המסמכים המוחזרים בצורה הבאה:
tv> db.shows.find().sort({"rating.average": -1}).skip(40).limit(5)
בדוגמה הזו נקבל חזרה 5 מסמכים בלבד.
סדר הפעולות
אין חשיבות לסדר הפעולות בדוגמאות האלו. למשל אם נכתוב את ה-skip ראשון ואז את ה-sort, עדיין יתבצע ה-sort ראשון ועל גבי התוצאות הממויינות יהיה skip של מספר מסמכים. כשנלמד בהמשך שימוש ב-aggregate נראה שיש חשיבות לסדר הפעולות.
החזרת שדות ספציפיים על ידי שימוש ב-projection
לפעמים עדיף להגביל את השדות המוחזרים אלינו. למשל, למסמכים של collection ה-shows שאנו משתמשים בו בדוגמאות כאן, יש הרבה שדות. נראה מסמך אחד לדוגמה:
tv> db.shows.find().limit(1) [ { _id: ObjectId("645dedfaf1bbd54a3d199ce7"), id: 3, url: 'http://www.tvmaze.com/shows/3/bitten', name: 'Bitten', type: 'Scripted', language: 'English', genres: [ 'Drama', 'Horror', 'Romance' ], status: 'Ended', runtime: 60, premiered: '2014-01-11', officialSite: 'http://bitten.space.ca/', schedule: { time: '22:00', days: [ 'Friday' ] }, rating: { average: 7.6 }, weight: 75, network: { id: 7, name: 'Space', country: { name: 'Canada', code: 'CA', timezone: 'America/Halifax' } }, webChannel: null, externals: { tvrage: 34965, thetvdb: 269550, imdb: 'tt2365946' }, image: { medium: 'http://static.tvmaze.com/uploads/images/medium_portrait/0/15.jpg', original: 'http://static.tvmaze.com/uploads/images/original_untouched/0/15.jpg' }, summary: '<p>Based on the critically acclaimed series of novels from Kelley Armstrong.
Set in Toronto and upper New York State, <b>Bitten</b> follows the adventures of
28-year-old Elena Michaels, the world's only female werewolf. An orphan, Elena thoughtshe finally found her "happily ever after" with her new love Clayton, until her lifechanged forever. With one small bite, the normal life she craved was taken away andshe was left to survive life with the Pack.</p>',
updated: 1534079818, _links: { self: { href: 'http://api.tvmaze.com/shows/3' }, previousepisode: { href: 'http://api.tvmaze.com/episodes/631862' } } } ]
וכשמריצים שאילתות שמחזירות מסמכים רבים כל המידע הזה צריך להישלח, וזה כמובן מעמיס את הרשת, ולפעמים גם גורם לבלגן. לכן לפעמים יהיה יותר נוח לבקש שרק חלק מהשדות יחזרו.
אם אנחנו רוצים לקבל חזרה רק את השדות name ו-runtime נוכל לעשות זאת כך:
tv> db.shows.find({ }, {name: 1, runtime: 1}).limit(1)
[
{
_id: ObjectId("645dedfaf1bbd54a3d199ce7"),
name: 'Bitten',
runtime: 60
}
]כפי שלמדנו, הסוגריים הראשונים זה הפילטר, ולכן כאן הם ריקים כי לא רצינו לסנן שום מסמך.
הסוגריים השניים זה ה-projection, ובו ביקשנו לקבל חזרה רק את השדות שמעניינים אותנו.
כפי שראים, גם השדה id_ חזר, למרות שלא ביקשנו אותו. השדה הזה חוזר תמיד כברירת מחדל, ואם אנחנו לא רוצים אותו נצטרך לציין את זה במפורש ע"י הערך 0 באופן הבא:
_id: 0
גם בשדות שיש בתוכם כמה שדות (nested fields) ניתן לקבוע מה בדיוק יחזור. למשל בתוך השדה network יש 3 שדות, ואם אנחנו רוצים שיחזור רק השדה id נכתוב זאת כך:
tv> db.shows.find({}, {name: 1, runtime: 1, _id: 0, "network.id": 1}).limit(1)
[ { name: 'Bitten', runtime: 60, network: { id: 7 } } ]שימוש ב-projection עבור מערכים
כמו שניתן להשתמש ב-projection כדי להחזיר רק חלק מהשדות, כך גם ניתן לקבוע אילו ערכים שיש במערכים יוחזרו. ישנן מספר שיטות לזה.
שיטה ראשונה היא ע"י שימוש באופרטור $ בצורה הבאה:
tv> db.shows.find({genres: "Drama"}, {"genres.$":1})
[
{ _id: ObjectId("645dedfaf1bbd54a3d199ce7"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199ce8"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199ce9"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cea"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199ceb"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199ced"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cee"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cef"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf0"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf1"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf2"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf3"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf4"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf5"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf7"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf8"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf9"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cfa"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cfb"), genres: [ 'Drama' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cfd"), genres: [ 'Drama' ] }
]
Type "it" for moreבפילטר ביקשנו שיחזרו רק הסרטים שבמערך ה-genres שלהם יש את הערך Drama. ובחלק של ה-projection ביקשנו שיחזור רק הערך הראשון שניתקלנו בו במערך כשהוחלט שהמסמך מתאים לשאילתא שלנו, לכן חזר רק הערך Drama במערך ה-genres.
כדי להבין טוב יותר נראה את השאילתא הבאה:
tv> db.shows.find({genres: {$all: ["Drama", "Horror"]}}, {"genres.$":1})
[
{ _id: ObjectId("645dedfaf1bbd54a3d199ce7"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf4"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf5"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf9"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cfb"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cfe"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199d01"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199d04"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199d20"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199d82"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199d9b"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199da2"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199da3"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199da6"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199db5"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199dba"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199dc8"), genres: [ 'Horror' ] }
]כפי שרואים, בכל המקרים חזר רק הערך Horror. הסיבה לכך היא שביקשנו בפילטר למצוא רק מסמכים שיש במערך שלהם גם את הערך Drama וגם את הערך Horror. בכל אחד מהמסמכים הוא בהתחלה חיפש את הערך Drama ורק לאחר מכן את הערך Horror. רק כשהערך Horror נמצא הוחלט שהמסמך הזה צריך לחזור, לכן זה הערך היחיד שחזר כי הוא בעצם הערך הראשון במערך ברגע שהוחלט שהמסמך צריך לחזור.
שיטה שניה היא ע"י elemMatch וכך אפשר לציין בדיוק איזה ערך מהמערך אנחנו רוצים שיחזור. למשל אם אנחנו רוצים למצוא את כל הסרטים של Drama אבל מעוניינים שבמערך יחזור רק הערך של Horror:
tv> db.shows.find({genres: "Drama"}, {genres: {$elemMatch: {$eq: "Horror"}}})
[
{ _id: ObjectId("645dedfaf1bbd54a3d199ce7"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199ce8") },
{ _id: ObjectId("645dedfaf1bbd54a3d199ce9") },
{ _id: ObjectId("645dedfaf1bbd54a3d199cea") },
{ _id: ObjectId("645dedfaf1bbd54a3d199ceb") },
{ _id: ObjectId("645dedfaf1bbd54a3d199ced") },
{ _id: ObjectId("645dedfaf1bbd54a3d199cee") },
{ _id: ObjectId("645dedfaf1bbd54a3d199cef") },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf0") },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf1") },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf2") },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf3") },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf4"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf5"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf7") },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf8") },
{ _id: ObjectId("645dedfaf1bbd54a3d199cf9"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cfa") },
{ _id: ObjectId("645dedfaf1bbd54a3d199cfb"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199cfd") }
]כמובן שאין צורך שהפילטר וה-projection יהיו על אותם שדות. למשל אם אנחנו רוצים את כל המסמכים שיש להם ממוצע רייטינג גבוה מ-9 ואנחנו רוצים לקבל במערך ה-genres רק את הערך Horror, נכתוב זאת כך:
tv> db.shows.find({"rating.average": {$gt: 9}}, {genres: {$elemMatch: {$eq: "Horror"}}})
[
{ _id: ObjectId("645dedfaf1bbd54a3d199cff"), genres: [ 'Horror' ] },
{ _id: ObjectId("645dedfaf1bbd54a3d199d36") },
{ _id: ObjectId("645dedfaf1bbd54a3d199d84") },
{ _id: ObjectId("645dedfaf1bbd54a3d199d8c") },
{ _id: ObjectId("645dedfaf1bbd54a3d199d8d") },
{ _id: ObjectId("645dedfaf1bbd54a3d199daa") },
{ _id: ObjectId("645dedfaf1bbd54a3d199dc1") }
]ניתן גם להגביל את מספר הערכים שחוזרים במערך על ידי האופרטור slice. למשל אם אנחנו רוצים שיחזרו בכל מערך רק 2 ערכים ראשונים, נכתוב:
tv> db.shows.find({"rating.average": {$gt: 9}}, {genres: {$slice: 2}, name: 1}).limit(3)
[
{
_id: ObjectId("645dedfaf1bbd54a3d199cff"),
name: 'Berserk',
genres: [ 'Anime', 'Fantasy' ]
},
{
_id: ObjectId("645dedfaf1bbd54a3d199d36"),
name: 'Game of Thrones',
genres: [ 'Drama', 'Adventure' ]
},
{
_id: ObjectId("645dedfaf1bbd54a3d199d84"),
name: 'Breaking Bad',
genres: [ 'Drama', 'Crime' ]
}
]אפשר גם להגדיר ב-slice לדלג על חלק מהערכים הראשונים ואז להחזיר כמות מסויימת. עושים את זה על ידי מערך בערך של ה-slice. למשל בדוגמה הבאה ביקשתי שידלג על הערך הראשון ויחזיר שני ערכים.
tv> db.shows.find({"rating.average": {$gt: 9}}, {genres: {$slice: [1, 2]}, name: 1}).limit(3) [ { _id: ObjectId("645dedfaf1bbd54a3d199cff"), name: 'Berserk', genres: [ 'Fantasy', 'Horror' ] }, { _id: ObjectId("645dedfaf1bbd54a3d199d36"), name: 'Game of Thrones', genres: [ 'Adventure', 'Fantasy' ] }, { _id: ObjectId("645dedfaf1bbd54a3d199d84"), name: 'Breaking Bad', genres: [ 'Crime', 'Thriller' ] } ]
פרק 6: פעולות Update
גם פה יש לנו שתי פקודות בסיסיות: updateOne, updateMany.
אחד הסרטים בקולקשיין shows שלנו נקרא Grimm:
tv> db.shows.find({name: "Grimm"}) [ { _id: ObjectId("645dedfaf1bbd54a3d199cf1"), id: 10, url: 'http://www.tvmaze.com/shows/10/grimm', name: 'Grimm', type: 'Scripted', language: 'English', genres: [ 'Drama', 'Crime', 'Supernatural' ], status: 'Ended', runtime: 60, premiered: '2011-10-28', officialSite: 'http://www.nbc.com/grimm', schedule: { time: '20:00', days: [ 'Friday' ] }, rating: { average: 8.5 }, weight: 95, network: { id: 1, name: 'NBC', country: { name: 'United States', code: 'US', timezone: 'America/New_York' } }, webChannel: null, externals: { tvrage: 28352, thetvdb: 248736, imdb: 'tt1830617' }, image: { medium: 'http://static.tvmaze.com/uploads/images/medium_portrait/69/174906.jpg', original: 'http://static.tvmaze.com/uploads/images/original_untouched/69/174906.jpg' }, summary: '<p><b>Grimm </b>is a drama series inspired by the classic Grimm Brothers' Fairy Tales. After Portland homicide detective Nick Burkhardt discovers he's descended from an elite line of criminal profilers known as "Grimms", he increasingly finds his responsibilities as a detective at odds with his new responsibilities as a Grimm.</p>`, updated: 1531998068, _links: { self: { href: 'http://api.tvmaze.com/shows/10' }, previousepisode: { href: 'http://api.tvmaze.com/episodes/1009811' } } } ]
כדי לשנות את השדה runtime שלו נכתוב:
tv> db.shows.updateOne({name: "Grimm"},{$set: {runtime: 30}})
{
acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0
}כפי שרואים מהפלט, מסמך אחד עודכן.
אם נריץ שוב את אותה הפקודה:
tv> db.shows.updateOne({name: "Grimm"},{$set: {runtime: 30}}) { acknowledged: true, insertedId: null, matchedCount: 1, modifiedCount: 0, upsertedCount: 0 }
מונגו מספיק חכם לראות שהשינוי שדרשנו לא ישפיע על המסמך כיון שהמידע הקיים זהה למידע שאנו רוצים להכניס, ולכן נקבל בפלט שמספר המסמכים שעודכנו הוא אפס.
בפקודת set אפשר לעדכן כמה שדות בבת אחת למשל בצורה הבאה:
tv> db.shows.updateOne({name: "Grimm"},{$set: {runtime: 30, "rating.average": 8}})
{
acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0
}גם השדה rating.average עודכן עכשיו (הערך בפלט של modifiedCount מציין את מספר המסמכים שעודכנו ולא את מספר השדות שעודכנו).
חשוב לציין שפקודות ה-update מעדכנות רק את השדות שצוינו ולא משנות את שאר השדות של המסמך.
נעבור לפקודת updateMany. נבדוק בקולקשיין שלנו כמה סרטים יש לנו שהשפה שלהם איננה אנגלית:
tv> db.shows.find({language: {$ne: "English"}}).count()
4עכשיו נעדכן את כל המסמכים האלו עם שדה חדש שנקרא isEnglish שיקבל את הערך false.
tv> db.shows.updateMany({language: {$ne: "English"}}, {$set: {isEnglish: false}})
{
acknowledged: true,
insertedId: null,
matchedCount: 4,
modifiedCount: 4,
upsertedCount: 0
}כפי שרואים מהפלט, ארבעה מסמכים עודכנו. נראה אחד מהם:
tv> db.shows.findOne({language: {$ne: "English"}}) { _id: ObjectId("645dedfaf1bbd54a3d199cfe"), id: 26, url: 'http://www.tvmaze.com/shows/26/hellsing-ultimate', name: 'Hellsing Ultimate', type: 'Animation', language: 'Japanese', genres: [ 'Drama', 'Action', 'Anime', 'Horror' ], status: 'Ended', runtime: 50, premiered: '2006-02-10', officialSite: null, schedule: { time: '12:00', days: [ 'Wednesday' ] }, rating: { average: 8.1 }, weight: 0, network: { id: 159, name: 'TBS', country: { name: 'Japan', code: 'JP', timezone: 'Asia/Tokyo' } }, webChannel: null, externals: { tvrage: 29109, thetvdb: 263688, imdb: 'tt0495212' }, image: { medium: 'http://static.tvmaze.com/uploads/images/medium_portrait/22/55037.jpg', original: 'http://static.tvmaze.com/uploads/images/original_untouched/22/55037.jpg' }, summary: "<p><b>Hellsing Ultimate</b>, unlike the 13-part <i>Hellsing</i> series, follows the manga of the same name very closely. Alucard being the main protagonist and anti-hero/vampire. <i>Hellsing Ultimate</i> is a 10-part series of OVAs whereby lucard turns Sera's into a vampire. The main focus of the plot being on an enemy neo-nazi group.</p>", updated: 1504676814, _links: { self: { href: 'http://api.tvmaze.com/shows/26' }, previousepisode: { href: 'http://api.tvmaze.com/episodes/1437' } }, isEnglish: false }
עדכון ערכים מספריים
האופרטור inc
ניתן לשנות ערכים מספריים ע"י השמה של ערך אחר אם משתמשים ב-set, וניתן גם להוסיף ולחסר ערכים מספריים אם משתמשים באופרטור inc.
נדגים את זה על הסרט Bitten.
tv> db.shows.findOne({name: "Bitten"}, {runtime: 1})
{ _id: ObjectId("645dedfaf1bbd54a3d199ce7"), runtime: 60 }כפי שרואים, הערך של שדה runtime שווה 60.
נגדיל את ערכו ב-5 ע"י הפקודה הבאה:
tv> db.shows.updateOne({name: "Bitten"}, {$inc: {runtime: 5}})
{
acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0
}נבדוק שהערך באמת עלה:
tv> db.shows.findOne({name: "Bitten"}, {runtime: 1})
{ _id: ObjectId("645dedfaf1bbd54a3d199ce7"), runtime: 65 }כדי להפחית נשתמש באותו אופרטור רק עם סימן מינוס:
tv> db.shows.updateOne({name: "Bitten"}, {$inc: {runtime: -7}})
{
acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0
}נבדוק שהערך ירד הפעם:
tv> db.shows.findOne({name: "Bitten"}, {runtime: 1})
{ _id: ObjectId("645dedfaf1bbd54a3d199ce7"), runtime: 58 }אם ננסה להגדיל או להוריד את הערך ובאותה פקודה ננסה גם לשנות את הערך ע"י פקודת set נקבל שגיאה:
tv> db.shows.updateOne({name: "Bitten"}, {$inc: {runtime: -7}, $set: {runtime: 20}})
MongoServerError: Updating the path 'runtime' would create a conflict at 'runtime'האופרטור mul
ע"י האופרטור mul ניתן לעדכן ערך ע"י הכפלה בערך מסוים.
נמשיך בדוגמה הקודמת. אם אנחנו רוצים לעדכן את השדה runtime שיהיה פי 2 מהערך הנוכחי:
tv> db.shows.updateOne({name: "Bitten"}, {$mul: {runtime: 2}})
{
acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0
}נבדוק את הערך עכשיו:
tv> db.shows.findOne({name: "Bitten"}, {runtime: 1})
{ _id: ObjectId("645dedfaf1bbd54a3d199ce7"), runtime: 116 }אופרטורים min/max
האופרטור min מאפשר לנו לעדכן ערך של שדה מסוים במידה והערך שציינו קטן יותר מהערך הנוכחי של אותו שדה.
נמשיך בדוגמה הקודמת. אם אנחנו רוצים לעדכן את השדה runtime ל-50 רק אם הערך הנוכחי שלו גבוה מ-50:
tv> db.shows.updateOne({name: "Bitten"}, {$min: {runtime: 50}})
{
acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0
}נבדוק את הערך עכשיו:
tv> db.shows.findOne({name: "Bitten"}, {runtime: 1})
{ _id: ObjectId("645dedfaf1bbd54a3d199ce7"), runtime: 50 }עכשיו שהערך הוא 50, אם נשתמש ב-min עם ערך גבוה מ-50 נראה שזה לא מתעדכן:
tv> db.shows.updateOne({name: "Bitten"}, {$min: {runtime: 55}})
{
acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 0,
upsertedCount: 0
}נבדוק את הערך:
tv> db.shows.findOne({name: "Bitten"}, {runtime: 1})
{ _id: ObjectId("645dedfaf1bbd54a3d199ce7"), runtime: 50 }האופרטור max, עושה את אותה פעולה במידה והערך שציינו גדול יותר מהערך הנוכחי של אותו שדה:
tv> db.shows.updateOne({name: "Bitten"}, {$max: {runtime: 55}})
{
acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0
}
tv> db.shows.findOne({name: "Bitten"}, {runtime: 1})
{ _id: ObjectId("645dedfaf1bbd54a3d199ce7"), runtime: 55 }בשני המקרים, אם השדה לא קיים הוא יווצר עם הערך ששלחנו.
מחיקת שדות
ניתן למחוק שדות ע"י שימוש באופרטור unset.
אם למשל יש צורך למחוק את השדה weight לכל הסרטים שאורכם גדול יותר מ-60, נעשה זאת כך:
tv> db.shows.updateMany({runtime: {$gt: 60}}, {$unset: {weight: ""}}) { acknowledged: true, insertedId: null, matchedCount: 2, modifiedCount: 2, upsertedCount: 0 }
הערך שכתבתי ב-weight זה פשוט גרשיים בלי כלום כי כך מקובל לכתוב אבל זה לא משנה מה הערך. מה שחשוב זה שם השדה.
לפי הפלט רואים שרק 2 מסמכים עודכנו. נראה אותם:
tv> db.shows.find({runtime: {$gt: 60}})
[
{
_id: ObjectId("645dedfaf1bbd54a3d199d1d"),
id: 70,
url: 'http://www.tvmaze.com/shows/70/the-voice',
name: 'The Voice',
type: 'Reality',
language: 'English',
genres: [ 'Family', 'Music' ],
status: 'Running',
runtime: 120,
premiered: '2011-04-26',
officialSite: 'http://www.nbc.com/the-voice',
schedule: { time: '20:00', days: [ 'Monday', 'Tuesday' ] },
rating: { average: 7.3 },
network: {
id: 1,
name: 'NBC',
country: {
name: 'United States',
code: 'US',
timezone: 'America/New_York'
}
},
webChannel: null,
externals: { tvrage: 27447, thetvdb: 247824, imdb: 'tt1839337' },
image: {
medium: 'http://static.tvmaze.com/uploads/images/medium_portrait/146/365331.jpg',
original: 'http://static.tvmaze.com/uploads/images/original_untouched/146/365331.jpg'
},
summary: '<p><b>The Voice</b> is a reality singing competition show where the idea is to find new singing talent via a series of itions.</p>',
updated: 1536584006,
_links: {
self: { href: 'http://api.tvmaze.com/shows/70' },
previousepisode: { href: 'http://api.tvmaze.com/episodes/1454416' },
nextepisode: { href: 'http://api.tvmaze.com/episodes/1482230' }
}
},
{
_id: ObjectId("645dedfaf1bbd54a3d199d1e"),
id: 71,
url: 'http://www.tvmaze.com/shows/71/dancing-with-the-stars',
name: 'Dancing with the Stars',
type: 'Reality',
language: 'English',
genres: [ 'Music' ],
status: 'Running',
runtime: 120,
premiered: '2005-06-01',
officialSite: 'http://abc.go.com/shows/dancing-with-the-stars',
schedule: { time: '20:00', days: [ 'Monday' ] },
rating: { average: 4.7 },
network: {
id: 3,
name: 'ABC',
country: {
name: 'United States',
code: 'US',
timezone: 'America/New_York'
}
},
webChannel: null,
externals: { tvrage: 3220, thetvdb: 79590, imdb: 'tt0463398' },
image: {
medium: 'http://static.tvmaze.com/uploads/images/medium_portrait/0/501.jpg',
original: 'http://static.tvmaze.com/uploads/images/original_untouched/0/501.jpg'
},
summary: '<p><b>Dancing with the Stars</b> is an american dance competition show and especially the american version of the british w <i>Strictly Come Dancing</i>.</p>',
updated: 1532455112,
_links: {
self: { href: 'http://api.tvmaze.com/shows/71' },
previousepisode: { href: 'http://api.tvmaze.com/episodes/1446662' },
nextepisode: { href: 'http://api.tvmaze.com/episodes/1501076' }
}
}
]כפי שניתן לראות, השדה weight לא קיים יותר במסמכים אלו.
רק כדי לוודא שלא פספסנו מסמכים, נבדוק כמה מסמכים יש שבהם ה-runtime לא גדול מ-60:
tv> db.shows.find({runtime: {$not: {$gt: 60}}}).count()
238ביחד עם שני המסמכים שעודכנו זה 240 מסמכים שזה גודל הקולקשיין, אז נראה שהכל בסדר.
שינוי שם שדות
האופרטור rename מאפשר לשנות שם של שדה.
נשנה לכל המסמכים את השדה שנקרא network ל-main network:
tv> db.shows.updateMany({}, {$rename: {network: "main network"}})
{
acknowledged: true,
insertedId: null,
matchedCount: 240,
modifiedCount: 240,
upsertedCount: 0
}נראה מסמך אחד:
tv> db.shows.findOne({}) { _id: ObjectId("645dedfaf1bbd54a3d199ce7"), id: 3, url: 'http://www.tvmaze.com/shows/3/bitten', name: 'Bitten', type: 'Scripted', language: 'English', genres: [ 'Drama', 'Horror', 'Romance' ], status: 'Ended', runtime: 50, premiered: '2014-01-11', officialSite: 'http://bitten.space.ca/', schedule: { time: '22:00', days: [ 'Friday' ] }, rating: { average: 7.6 }, weight: 75, webChannel: null, externals: { tvrage: 34965, thetvdb: 269550, imdb: 'tt2365946' }, image: { medium: 'http://static.tvmaze.com/uploads/images/medium_portrait/0/15.jpg', original: 'http://static.tvmaze.com/uploads/images/original_untouched/0/15.jpg' }, summary: '<p>Based on the critically acclaimed series of novels from Kelley Armstrong. Set in Toronto and upper New York State, Bitten</b> follows the adventures of 28-year-old Elena Michaels, the world's only female werewolf. An orphan, Elena thought she finally nd her "happily ever after" with her new love Clayton, until her life changed forever. With one small bite, the normal life she craved taken away and she was left to survive life with the Pack.</p>`, updated: 1534079818, _links: { self: {ef: 'http://api.tvmaze.com/shows/3' }, previousepisode: { href: 'http://api.tvmaze.com/episodes/631862' } }, 'main network': { id: 7, name: 'Space', country: { name: 'Canada', code: 'CA', timezone: 'America/Halifax' } } }
האופרטור upsert
האופרטור upsert (שילוב של המילים update+insert) מאפשר לנו לעדכן מסמך מסוים אם הוא קיים וליצור אותו אם הוא לא קיים. במציאות נתקלים בהמון מקרים שיש צורך בדיוק בזה.
למשל, אם אני רוצה לעדכן את השדה runtime שיהיה שווה ל-75 בסרט שנקרא "Am Israel Hay", אם יש כזה סרט, ואם אין אז אני רוצה שיווצר לי מסמך כזה, אני יכול להשתמש באופרטור upsert.
בדיפולט הערך של upsert הוא false ולכן אם אין מסמך כזה לא יווצר מסמך חדש:
tv> db.shows.updateOne({name: "Am Israel Hay"}, {$set: {runtime: 75}})
{
acknowledged: true,
insertedId: null,
matchedCount: 0,
modifiedCount: 0,
upsertedCount: 0
}אבל אם נשתמש ב-upsert כ-true:
tv> db.shows.updateOne({name: "Am Israel Hay"}, {$set: {runtime: 75}}, {upsert: true})
{
acknowledged: true,
insertedId: ObjectId("64a130461804e5d28146ce99"),
matchedCount: 0,
modifiedCount: 0,
upsertedCount: 1
}שימו לב שהאופרטור הזה נמצא בקלט השלישי בפקודה. החלק הראשון הוא ה-query. השני הוא ה-update והשלישי options.
נבדוק שהוא באמת קיים:
tv> db.shows.find({name: "Am Israel Hay"})
[
{
_id: ObjectId("64a130461804e5d28146ce99"),
name: 'Am Israel Hay',
runtime: 75
}
]שימו לב ש-מונגו מספיק חכם להכניס גם את השדה name שיהיה חלק מהמסך החדש למרות שהוא לא היה חלק מהשדות שהיו באופרטור set.
שינוי איבר במערך ע"י שימוש באופרטור $
הפעם נשתמש בקולקשיין פשוט שנראה כך:
persons> db.users.find()
[
{
_id: ObjectId("647c3a194125808a1a7518f5"),
name: 'Dani',
kids: [
{ name: 'Yair', age: 10, gender: 'male' },
{ name: 'Sara', age: 4, gender: 'female' }
],
friends: [ { name: 'Moshe', age: 22 }, { name: 'Ehud', age: 23 } ]
},
{
_id: ObjectId("647c3a194125808a1a7518f6"),
name: 'Roni',
friends: [ { name: 'Yosi', age: 25 }, { name: 'Sasi', age: 27 } ],
kids: [
{ name: 'Avigail', age: 8, gender: 'female' },
{ name: 'Orit', age: 4, gender: 'female' }
]
},
{
_id: ObjectId("647d6f8951915991c912a117"),
name: 'David',
friends: [ { name: 'Gilad', age: 32 }, { name: 'Tal', age: 40 } ],
kids: [
{ name: 'Yair', age: 5, gender: 'male' },
{ name: 'Idan', age: 2, gender: 'male' }
]
}
]אני רוצה להוסיף לכל משתמש שיש לו ילדה מגיל 7 ומעלה שדה נוסף שנקרא girlInSchool שיהיה true.
בהתחלה נחפש את המשתמשים המתאימים.
אם אני אחפש ע"י שימוש בפקודה הבאה:
persons> db.users.find({$and: [{"kids.gender": "female"}, {"kids.age": {$gte: 7}}]})
[
{
_id: ObjectId("647c3a194125808a1a7518f5"),
name: 'Dani',
kids: [
{ name: 'Yair', age: 10, gender: 'male' },
{ name: 'Sara', age: 4, gender: 'female' }
],
friends: [ { name: 'Moshe', age: 22 }, { name: 'Ehud', age: 23 } ]
},
{
_id: ObjectId("647c3a194125808a1a7518f6"),
name: 'Roni',
friends: [ { name: 'Yosi', age: 25 }, { name: 'Sasi', age: 27 } ],
kids: [
{ name: 'Avigail', age: 8, gender: 'female' },
{ name: 'Orit', age: 4, gender: 'female' }
]
}
]כפי שרואים, קיבלנו את דני ורוני. לרוני יש באמת בת מעל גיל 7.
את דני קיבלנו כיון שיש לו בת וגם ילד מעל גיל 7, אבל השאילתא שלנו לא דרשה שהילד מעל גיל 7 יהיה דווקא בת ולא בן.
השאילתא הנכונה היא כמו שדיברנו לעיל ע"י שימוש באופרטור elemMatch שמאפשר לנו לפלטר לפי אלמנט מסוים, ככה שכל התנאים יתקיימו באותו אלמנט:
persons> db.users.find({kids: {$elemMatch: {gender: "female", age: {$gte: 7}}}})
[
{
_id: ObjectId("647c3a194125808a1a7518f6"),
name: 'Roni',
friends: [ { name: 'Yosi', age: 25 }, { name: 'Sasi', age: 27 } ],
kids: [
{ name: 'Avigail', age: 8, gender: 'female' },
{ name: 'Orit', age: 4, gender: 'female' }
]
}
]השאילתא הזו תחזיר לנו מסמכים שיש בשדה kids אלמנט שבו ה-gender הוא female וה-age גדול או שווה ל-7.
נמשיך למשימה שלנו שהיא הוספה של שדה נוסף שנקרא girlInSchool שיהיה true למשתמשים הרלוונטים. לצורך כך נשתמש בפקודה הבאה:
persons> db.users.updateMany({kids: {$elemMatch: {gender: "female", age: {$gte: 7}}}}, {$set: {"kids.$.girlInSchool": true}})
{
acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0
}הפילטר זהה למה שראינו בפקודה הקודמת. ולצורך ה-update השתמשנו ב-set כששם השדה הוא: kids.$.girlInSchool.
סימן הדולר מביא לנו את כל המסמכים שתואמים לפילטר שהשתמשנו בו. וכך בעצם כל אלמנט במערך kids שתואם לפילטר שלנו יעודכן ויקבל את השדה החדש.
נבדוק את הקולקשיין:
persons> db.users.find() [ { _id: ObjectId("647c3a194125808a1a7518f5"), name: 'Dani', kids: [ { name: 'Yair', age: 10, gender: 'male' }, { name: 'Sara', age: 4, gender: 'female' } ], friends: [ { name: 'Moshe', age: 22 }, { name: 'Ehud', age: 23 } ] }, { _id: ObjectId("647c3a194125808a1a7518f6"), name: 'Roni', friends: [ { name: 'Yosi', age: 25 }, { name: 'Sasi', age: 27 } ], kids: [ { name: 'Avigail', age: 8, gender: 'female', girlInSchool: true }, { name: 'Orit', age: 4, gender: 'female' } ] }, { _id: ObjectId("647d6f8951915991c912a117"), name: 'David', friends: [ { name: 'Gilad', age: 32 }, { name: 'Tal', age: 40 } ], kids: [ { name: 'Yair', age: 5, gender: 'male' }, { name: 'Idan', age: 2, gender: 'male' } ] } ]
שינוי כל האיברים במערך ע"י שימוש באופרטור []$
לפעמים יש צורך לשנות את כל האיברים במערך לפי פילטר מסוים. למשל נגיד שאנחנו רוצים להכניס לכל ילד מעל גיל 3 את השדה bigKid שיהיה true.
היה אפשר לחשוב שהפקודה הבאה תעשה את העבודה:
persons> db.users.updateMany({"kids.age": {$gt: 3}}, {$set: {"kids.$.bigKid": true}})אבל בפועל, מה שקורה זה שרק האיבר הראשון בכל מערך מתעדכן ושאר האיברים, למרות שהם עוברים את הפילטר, לא מתעדכנים.
כדי לשנות את כל האיברים צריך להוסיף סוגריים מרובעים לאחר סימן הדולר:
persons> db.users.updateMany({"kids.age": {$gt: 3}}, {$set: {"kids.$[].bigKid": true}})
{
acknowledged: true,
insertedId: null,
matchedCount: 3,
modifiedCount: 3,
upsertedCount: 0
}עכשיו נבדוק את הנתונים:
persons> db.users.find() [ { _id: ObjectId("647c3a194125808a1a7518f5"), name: 'Dani', kids: [ { name: 'Yair', age: 10, gender: 'male', bigKid: true }, { name: 'Sara', age: 4, gender: 'female', bigKid: true } ], friends: [ { name: 'Moshe', age: 22 }, { name: 'Ehud', age: 23 } ] }, { _id: ObjectId("647c3a194125808a1a7518f6"), name: 'Roni', friends: [ { name: 'Yosi', age: 25 }, { name: 'Sasi', age: 27 } ], kids: [ { name: 'Avigail', age: 8, gender: 'female', girlInSchool: true, bigKid: true }, { name: 'Orit', age: 4, gender: 'female', bigKid: true } ] }, { _id: ObjectId("647d6f8951915991c912a117"), name: 'David', friends: [ { name: 'Gilad', age: 32 }, { name: 'Tal', age: 40 } ], kids: [ { name: 'Yair', age: 5, gender: 'male', bigKid: true }, { name: 'Idan', age: 2, gender: 'male', bigKid: true } ] } ]
כפי שרואים, כל האיברים עודכנו. הפילטר מצא את כל המערכים שיש בהם ילד שגדול מגיל 3, ובמערכים האלו הוא עידכן את כל האיברים, כולל את הילדים שלא גדולים מגיל 3. זה לא בדיוק מה שרצינו. אנחנו רוצים לעדכן את כל הילדים שגדולים מגיל 3 אבל לא את אלה שקטנים מגיל 3.
כדי לקבל בדיוק את מה שאנחנו רוצים נשתמש בפקודה קצת יותר מורכבת. קודם כל נחזיר את הנתונים בקולקשיין שיהיו ללא השינוי האחרון:
persons> db.users.updateMany({"kids.age": {$gt: 3}}, {$unset: {"kids.$[].bigKid": ""}})
{
acknowledged: true,
insertedId: null,
matchedCount: 3,
modifiedCount: 3,
upsertedCount: 0
}ועכשיו נשתמש בפקודה הבא:
persons> db.users.updateMany(
{"kids.age": {$gt: 3}}, {$set: {"kids.$[item].bigKid": true}}, {arrayFilters: [{"item.age": {$gt: 3}}]})
{
acknowledged: true,
insertedId: null,
matchedCount: 3,
modifiedCount: 3,
upsertedCount: 0
}בפקודה הזו הוספנו בתוך הסוגריים המרובעים את item שזה שם שנתתי לאיברים במערך. אפשר לתת כל שם. ולאחר מכן בחלק השלישי (החלק של ה-options) השתמשתי ב-arrayFilters ובו אפשר לפלטר איזה איברים יעודכנו במערכים. אפשר להכניס כל פילטר אבל במקרה שלנו אנחנו רוצים להשתמש ב-item שמציין איבר מסוים במערך, כך שרק איבר שיש לו age גדול מ-3 יעודכן.
זה הקולקשיין שלנו עכשיו:
persons> db.users.find() [ { _id: ObjectId("647c3a194125808a1a7518f5"), name: 'Dani', kids: [ { name: 'Yair', age: 10, gender: 'male', bigKid: true }, { name: 'Sara', age: 4, gender: 'female', bigKid: true } ], friends: [ { name: 'Moshe', age: 22 }, { name: 'Ehud', age: 23 } ] }, { _id: ObjectId("647c3a194125808a1a7518f6"), name: 'Roni', friends: [ { name: 'Yosi', age: 25 }, { name: 'Sasi', age: 27 } ], kids: [ { name: 'Avigail', age: 8, gender: 'female', girlInSchool: true, bigKid: true }, { name: 'Orit', age: 4, gender: 'female', bigKid: true } ] }, { _id: ObjectId("647d6f8951915991c912a117"), name: 'David', friends: [ { name: 'Gilad', age: 32 }, { name: 'Tal', age: 40 } ], kids: [ { name: 'Yair', age: 5, gender: 'male', bigKid: true }, { name: 'Idan', age: 2, gender: 'male' } ] } ]
אפשר לראות שרק ילד מעל גיל 3 קיבל את השדה החדש. בקולקשיין שלנו רק עידן קטן מגיל 3 ולכן רק הוא לא קיבל את השדה החדש.
הוספת איבר למערך ע"י שימוש ב-push או addToSet
אם ננסה להוסיף איברים למערך ע"י set למשל בצורה הבאה:
db.users.updateOne({name: "Dani"}, {$set: {kids: [{name: 'Dudu', age: 7, gender: "male" }]}})
במקום שהאיבר החדש יתווסף למערך, הוא פשוט ידרוס את כל מה שיש במערך.
כדי להוסיף איבר למערך צריך להשתמש ב-push:
persons> db.users.updateOne({name: "Dani"}, {$push: {kids: {name: 'Dudu', age: 7, gender: "male"}}})
{
acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0
}נראה עכשיו את המסמך של דני:
persons> db.users.find({name: "Dani"})
[
{
_id: ObjectId("647c3a194125808a1a7518f5"),
name: 'Dani',
friends: [ { name: 'Moshe', age: 22 }, { name: 'Ehud', age: 23 } ],
kids: [
{ name: 'Yair', age: 10, gender: 'male', bigKid: true },
{ name: 'Sara', age: 4, gender: 'female', bigKid: true },
{ name: 'Dudu', age: 7, gender: 'male' }
]
}
]אופרטור דומה ל-push הוא האופרטור addToSet. ההבדל ביניהם הוא שאם נכניס את אותו איבר כמה פעמים עם push יהיה לנו במערך כמה איברים זהים. לעומת זאת, בשימוש ב-addToSet האיבר יתווסף רק אם הוא ייחודי ולא קיים במערך.
הוספת מספר איברים למערך ע"י שימוש ב-push עם-each וכן שימוש ב-sort, slice
כדי להוסיף כמה איברים בפקודה אחת נשתמש ב-each:
persons> db.users.updateOne({name: "Dani"}, {$push: {kids: {$each: [ {name: 'Lea', age: 6, gender: "female"}, {name: 'Dina', age: 11, gender: "female"}], $sort: {age: -1}}}})
{
acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0
}בפקודה הזו הכנסנו שתי ילדות (דינה ולאה). ובנוסף השתמשנו ב-sort (שימו לב שגם הוא נמצא בתוך האופרטור push) וביקשנו שהילדים ימויינו לפי הגיל בסדר יורד:
persons> db.users.find({name: "Dani"})
[
{
_id: ObjectId("647c3a194125808a1a7518f5"),
name: 'Dani',
friends: [ { name: 'Moshe', age: 22 }, { name: 'Ehud', age: 23 } ],
kids: [
{ name: 'Dina', age: 11, gender: 'female' },
{ name: 'Yair', age: 10, gender: 'male', bigKid: true },
{ name: 'Dudu', age: 7, gender: 'male' },
{ name: 'Lea', age: 6, gender: 'female' },
{ name: 'Sara', age: 4, gender: 'female', bigKid: true }
]
}
]שימו לב שהאופרטור sort מיין לנו גם את הילדים שכבר היו במערך לפני הפקודה ולא רק אלו שנוספו עכשיו.
אופרטור נוסף שבו אפשר להשתמש הוא slice. האופרטור הזה מאפשר לנו לחתוך את הנתונים כך שישארו רק חלק מהנתונים. למשל בפקודה הבאה נכתוב שני ילדים אבל בגלל שב-slice נכתוב ערך של 3 רק שלושה ילדים ישארו.
persons> db.users.updateOne({name: "Dani"}, {$push: {kids: {$each: [ {name: 'Zion', age: 5, gender: "male"}, {name: 'Riki', age: 12, gender: "female"}], $sort: {age: -1}, $slice: 3}}}) { acknowledged: true, insertedId: null, matchedCount: 1, modifiedCount: 1, upsertedCount: 0 }
הוספנו את ציון וריקי. מיינו את הילדים בסדר יורד וביקשנו להשאיר רק שלושה ילדים.
כמו שהפקודה sort פעלה גם על הנתונים שהיו כבר במערך לפני הפקודה, כך גם פקודת slice תפעל גם על הנתונים האלו ותשאיר לנו רק את שלושת הילדים הגדולים:
persons> db.users.find({name: "Dani"})
[
{
_id: ObjectId("647c3a194125808a1a7518f5"),
name: 'Dani',
friends: [ { name: 'Moshe', age: 22 }, { name: 'Ehud', age: 23 } ],
kids: [
{ name: 'Riki', age: 12, gender: 'female' },
{ name: 'Dina', age: 11, gender: 'female' },
{ name: 'Yair', age: 10, gender: 'male', bigKid: true }
]
}
]בדוגמה שלנו ה-slice לא ממש נראה שימושי אבל יש מקרים שאנחנו רוצים להשאיר ב-DB שלנו רק חלק מהנתונים ואז ה-slice יכול להיות מאוד שימושי.
הסרת איברים ממערך ע"י שימוש ב-pull ו-pop
כדי להסיר איברים מהמערך ניתן להשתמש ב-pull. למשל כדי להסיר את ריקי מרשימת הילדים נכתוב:
persons> db.users.updateOne({name: "Dani"}, {$pull: {kids: {name: "Riki"}}})
{
acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0
}נראה עכשיו את רשימת הילדים של דני:
persons> db.users.find({name: "Dani"})
[
{
_id: ObjectId("647c3a194125808a1a7518f5"),
name: 'Dani',
friends: [ { name: 'Moshe', age: 22 }, { name: 'Ehud', age: 23 } ],
kids: [
{ name: 'Dina', age: 11, gender: 'female' },
{ name: 'Yair', age: 10, gender: 'male', bigKid: true }
]
}
]ניתן גם להסיר את האיבר האחרון במערך ע"י pop בצורה הבאה:
persons> db.users.updateOne({name: "Dani"}, {$pop: {kids: 1}})
{
acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0
}נראה עכשיו את רשימת הילדים של דני:
persons> db.users.find({name: "Dani"})
[
{
_id: ObjectId("647c3a194125808a1a7518f5"),
name: 'Dani',
friends: [ { name: 'Moshe', age: 22 }, { name: 'Ehud', age: 23 } ],
kids: [ { name: 'Dina', age: 11, gender: 'female' } ]
}
]בצורה דומה ניתן להסיר את האיבר הראשון במערך אם נשתמש ב-pop עם ערך של מינוס 1.
פרק 7: מחיקת מסמכים
כמו בשאר הפקודות גם כאן יש שתי פקודות עיקריות deleteOne, deleteMany.
למשל כדי למחוק את המשתמש Dani נכתוב:
persons> db.users.deleteOne({name:'Dani'})
{ acknowledged: true, deletedCount: 1 }וכדי למחוק את כל המשתמשים שיש להם חברים נכתוב:
persons> db.users.deleteMany({friends: {$exists: true}})
{ acknowledged: true, deletedCount: 2 }כדי למחוק את כל המסמכים בקולקשיין נשאיר את הפילטר ריק:
persons> db.users.deleteMany({})שתי פקודות מסוכנות שצריך להבין טוב מה אנחנו עושים לפני שנשתמש בהן הן הפקודות שנועדו למחיקת קולקשיין ולמחיקת DB.
כדי למחוק קולקשיין נכתוב:
persons> db.users.drop()
trueכדי למחוק את כל ה-DB נכתוב:
persons> db.dropDatabase()
{ ok: 1, dropped: 'persons' }פרק 8: עבודה עם אינדקסים
אינדקסים יכולים לעזור לנו לקבל נתונים בצורה מהירה יותר מה-DB. עם זאת, אם לא עובדים איתם נכון הם עלולים גם להאט את העבודה שלנו.
מהם אינדקסים?
כשאנחנו כותבים שאילתא לחיפוש למשל:
db.users.find({name: Rafael})
מונגו עובר על כל המסמכים ובודק בכל אחד האם השדה name שווה ל-Rafael. לשיטה הזו קוראים collection scan. או בקיצור COLLSCAN. כשמספר המסמכים קטן זה תהליך מהיר. אבל כשיש לנו קולקשיין עם הרבה מסמכים השאילתא הזו יכולה לקחת זמן ארוך.
אינדקסים עוזרים לנו לקצר את זמן מציאת המסמכים. כשאנחנו קובעים ששדה מסוים הוא אינדקס - מונגו מייצר רשימה ממוינת של השדה הזה כך שקל מאוד למצוא ברשימה הזו ערך מסוים של השדה הזה. יחד עם השדה הוא שומר פוינטר למסמך המלא שהשדה הזה שייך לו, וכך החיפוש הרבה יותר מהיר.
כשאנחנו מבצעים חיפוש לפי שדה שיש לו אינדקס פעולת החיפוש תעשה בשיטה שנקראת index scan או בקיצור IXSCAN.
אם קבענו ששדה מסוים הוא אינדקס, בכל פעם שנכניס מסמך חדש - מונגו יקח את השדה הזה מהמסמך החדש ויאנדקס אותו (יוסיף אותו לרשימת האינדקס הממוינת). הפעולה הזו כמובן לוקחת זמן, ולכן כל פעולת כתיבה תהיה קצת יותר ארוכה. כמו כן, פעולות עדכון ומחיקת מסמך גם הן יגרמו לעדכון האינדקס ולכן יקחו קצת יותר זמן.
אם נאנדקס את כל השדות של כל מסמך, הפעולה הזו כבר עלולה להיות ארוכה באופן משמעותי ולכן צריך להחליט על כל שדה כמה אינדוקס שלו עוזר לנו לעומת הזמן הנוסף שהוא דורש מאיתנו בכתיבת מסמכים.
כדי לתרגל שימוש באינדקסים נשתמש בקובץ שנקרא persons.json ויש בו 5000 רשומות של לקוחות.
ניתן להוריד את הקובץ מכאן:
https://github.com/rafraph/filesForLearning/blob/main/persons.json
נכניס את המידע לתוך ה-DB ע"י כך שבטרמינל רגיל (לא mongosh) נגיע למיקום של הקובץ ונכתוב:
mongoimport persons.json -d clients -c contacts --jsonArray
כך נראה אחד המסמכים:
clients> db.contacts.findOne()
{
_id: ObjectId("64f583a34143c7c3332881de"),
gender: 'male',
name: { title: 'mr', first: 'harvey', last: 'chambers' },
location: {
street: '3287 high street',
city: 'carlow',
state: 'wexford',
postcode: 47671,
coordinates: { latitude: '-22.5329', longitude: '168.9462' },
timezone: {
offset: '+5:00',
description: 'Ekaterinburg, Islamabad, Karachi, Tashkent'
}
},
email: 'harvey.chambers@example.com',
login: {
uuid: '8f583f57-c999-4a5d-a8c1-d913b574c082',
username: 'greenrabbit148',
password: 'june',
salt: 'dAsaXJGK',
md5: 'e3759db2391b798ffea2cc168e1280fd',
sha1: 'a3e77fd5fdd75e3b173ceec6c3c1bbe5e83540cc',
sha256: '7564eac1899234d5902fadfb995303a58370232f54bee6adb26e25394e2ffddd'
},
dob: { date: '1988-05-27T00:14:03Z', age: 30 },
registered: { date: '2007-03-11T06:20:19Z', age: 11 },
phone: '061-265-5188',
cell: '081-146-8382',
id: { name: 'PPS', value: '5608572T' },
picture: {
large: 'https://randomuser.me/api/portraits/men/82.jpg',
medium: 'https://randomuser.me/api/portraits/med/men/82.jpg',
thumbnail: 'https://randomuser.me/api/portraits/thumb/men/82.jpg'
},
nat: 'IE'
}כדי להבין איך מונגו פועל נשתמש בפקודת explain אותה ניתן להוסיף לפקודת השאילתא שלנו כדי לקבל הסבר ממונגו על הצורה שבה הוא ביצע את השאילתא.
אם למשל אנחנו מחפשים את כל הלקוחות מעל גיל 50 (השדה age נמצא בתוך השדה dob). אז נכתוב את השאילתא יחד עם explain כך:
clients> db.contacts.explain().find({"dob.age": {$gt: 50}})
{
explainVersion: '1',
queryPlanner: {
namespace: 'clients.contacts',
indexFilterSet: false,
parsedQuery: { 'dob.age': { '$gt': 50 } },
queryHash: '08155E45',
planCacheKey: '08155E45',
maxIndexedOrSolutionsReached: false,
maxIndexedAndSolutionsReached: false,
maxScansToExplodeReached: false,
winningPlan: {
stage: 'COLLSCAN',
filter: { 'dob.age': { '$gt': 50 } },
direction: 'forward'
},
rejectedPlans: []
},
command: {
find: 'contacts',
filter: { 'dob.age': { '$gt': 50 } },
'$db': 'clients'
},
serverInfo: {
host: 'DELL-RAFAELJ',
port: 27017,
version: '6.0.5',
gitVersion: 'c9a99c120371d4d4c52cbb15dac34a36ce8d3b1d'
},
serverParameters: {
internalQueryFacetBufferSizeBytes: 104857600,
internalQueryFacetMaxOutputDocSizeBytes: 104857600,
internalLookupStageIntermediateDocumentMaxSizeBytes: 104857600,
internalDocumentSourceGroupMaxMemoryBytes: 104857600,
internalQueryMaxBlockingSortMemoryUsageBytes: 104857600,
internalQueryProhibitBlockingMergeOnMongoS: 0,
internalQueryMaxAddToSetBytes: 104857600,
internalDocumentSourceSetWindowFieldsMaxMemoryBytes: 104857600
},
ok: 1
}נסביר על חלק ממה שכתוב כאן.
מונגו בוחר באחת מכמה אפשרויות פעולה שיש לו. כל אפשרות נקראת plan. בשדה שנקרא winningPlan נראה את השיטה ש"ניצחה" ובה הוא בחר להשתמש בשביל השאילתא הנוכחית.
במקרה הנוכחי הוא בחר במעבר על כל הקולקשיין, מה שנקרא COLLSCAN.
בשדה rejectedPlans אנחנו אמורים לראות שיטות אחרות שהוא בחן ופסל אבל כשאין לנו אינדקסים אין לו שיטות נוספות לבחור מהן ולכן המערך הזה ריק.
ניתן לקבל עוד מידע אם בתוך פקודת explain נכניס פרמטר בגרשיים שנקרא "executionStats":
clients> db.contacts.explain("executionStats").find({"dob.age": {$gt: 50}}) { explainVersion: '1', queryPlanner: { namespace: 'clients.contacts', indexFilterSet: false, parsedQuery: { 'dob.age': { '$gt': 50 } }, queryHash: '08155E45', planCacheKey: '08155E45', maxIndexedOrSolutionsReached: false, maxIndexedAndSolutionsReached: false, maxScansToExplodeReached: false, winningPlan: { stage: 'COLLSCAN', filter: { 'dob.age': { '$gt': 50 } }, direction: 'forward' }, rejectedPlans: [] }, executionStats: { executionSuccess: true, nReturned: 2204, executionTimeMillis: 3, totalKeysExamined: 0, totalDocsExamined: 5000, executionStages: { stage: 'COLLSCAN', filter: { 'dob.age': { '$gt': 50 } }, nReturned: 2204, executionTimeMillisEstimate: 0, works: 5002, advanced: 2204, needTime: 2797, needYield: 0, saveState: 5, restoreState: 5, isEOF: 1, direction: 'forward', docsExamined: 5000 } }, …
בשדה executionStats.executionTimeMillis ניתן לראות כמה זמן לקחה השאילתא. במקרה שלי 3ms.
בשדה executionStats.totalDocsExamined ניתן לראות כמה מסמכים נסרקו בשביל לקבל את התשובה לשאילתא.
יצירת אינדקס
עכשיו ניצור אינדקס ונראה איך הוא משפיע.
כדי ליצור אינדקס נשתמש בפקודה הבאה:
clients> db.contacts.createIndex({"dob.age": 1})
dob.age_1השדה שאותו כתבנו, "dob.age", הוא השדה שאותו רוצים לאנדקס.
הערך יכול להיות 1 או מינוס 1. והוא יקבע אם האינדקס שיווצר יהיה ממוין בסדר עולה (1) או יורד (1-). למיטב ידיעתי אין השפעה אם הסדר הוא עולה או יורד ולכן אפשר תמיד פשוט לכתוב 1.
הפלט שקיבלנו - dob.age_1 הוא שם האינדקס שנוצר.
עכשיו נבדוק שוב את אותה השאילתא שניסינו מקודם:
clients> db.contacts.explain("executionStats").find({"dob.age": {$gt: 50}}) { explainVersion: '1', queryPlanner: { namespace: 'clients.contacts', indexFilterSet: false, parsedQuery: { 'dob.age': { '$gt': 50 } }, queryHash: '08155E45', planCacheKey: '3F4F0F60', maxIndexedOrSolutionsReached: false, maxIndexedAndSolutionsReached: false, maxScansToExplodeReached: false, winningPlan: { stage: 'FETCH', inputStage: { stage: 'IXSCAN', keyPattern: { 'dob.age': 1 }, indexName: 'dob.age_1', isMultiKey: false, multiKeyPaths: { 'dob.age': [] }, isUnique: false, isSparse: false, isPartial: false, indexVersion: 2, direction: 'forward', indexBounds: { 'dob.age': [ '(50, inf.0]' ] } } }, rejectedPlans: [] }, executionStats: { executionSuccess: true, nReturned: 2204, executionTimeMillis: 2, totalKeysExamined: 2204, totalDocsExamined: 2204, executionStages: { stage: 'FETCH', nReturned: 2204, executionTimeMillisEstimate: 0, works: 2205, advanced: 2204, needTime: 0, needYield: 0, saveState: 2, restoreState: 2, isEOF: 1, docsExamined: 2204, alreadyHasObj: 0, inputStage: { stage: 'IXSCAN', nReturned: 2204, executionTimeMillisEstimate: 0, works: 2205, advanced: 2204, needTime: 0, needYield: 0, saveState: 2, restoreState: 2, isEOF: 1, keyPattern: { 'dob.age': 1 }, indexName: 'dob.age_1', isMultiKey: false, multiKeyPaths: { 'dob.age': [] }, isUnique: false, isSparse: false, isPartial: false, indexVersion: 2, direction: 'forward', indexBounds: { 'dob.age': [ '(50, inf.0]' ] }, keysExamined: 2204, seeks: 1, dupsTested: 0, dupsDropped: 0 } } }, …
בזכות האינדקס זמן הריצה ירד ל-2ms.
ניתן גם לראות שעכשיו יש לנו שני execution stages. הראשון הוא IXSCAN (מסומן כ-inputStage).
הוא החזיר לנו 2204 keys של האינדקס כל אחד עם הפוינטר שלו למסמך שעליו הוא מצביע.
ה-stage הבא הוא ה-FETCH שמשתמש בפוינטרים האלו כדי ללכת ולהביא את המסמכים מה-DB.
ניתן גם לראות בשדה totalDocsExamined שמספר המסמכים שנסרקו הוא 2204. ולא 5000 כמו שהיה בלי אינדקס.
יצירת אינדקס ב-background
כשיש לנו הרבה מסמכים ואנחנו מייצרים אינדקס על שדה שמופיע הרבה פעמים או שדה שמורכב לאנדקס אותו (כמו שנראה בהמשך לגבי שדות טקסט) - יצירת האינדקס יכולה לקחת זמן.
בניסויים שאנחנו עושים בשביל למידה הזמן קצר מאוד, אבל במציאות כשיש לנו DB גדול עם מיליוני מסמכים - זמן יצירת האינדקס יכול להיות משמעותי.
בזמן שנוצר האינדקס לא ניתן לגשת לקולקשיין. למשל אי אפשר לתשאל אותו או להוסיף לו מסמך וכן שאר הפעולות חסומות עד שהאינדקס נוצר. וזה בגלל שיצירת האינדקס באופן דיפולטיבי היא בשיטת foreground. בשיטה הזו האינדקס נוצר מהר יותר אבל חוסם גישה לקולקשיין. במערכות production זה לא קביל שהקולקשיין חסום ולכן נצטרך ליצור אינדקס בשיטת ה-background.
בשיטה הזו האינדקס נוצר קצת לאט יותר אבל הקולקשיין לא נחסם.
כדי ליצור אינדקס ב-background נוסיף פרמטר לפקודת יצירת האינדקס בצורה הבאה:
clients> db.contacts.createIndex({"dob.age": 1}, {background: true})מחיקת אינדקס
ניתן למחוק אינדקס בצורה הבאה:
clients> db.contacts.dropIndex({"dob.age": 1})
{ nIndexesWas: 2, ok: 1 }או ע"י שימוש בשם האינדקס:
clients> db.contacts.dropIndex('dob.age_1') { nIndexesWas: 2, ok: 1 }
כדי לדעת את שם האינדקס ראו פיסקה הבאה.
הדפסת האינדקסים הקיימים
ניתן לראות את כל האינדקסים ע"י הפקודה:
clients> db.contacts.getIndexes()
[
{ v: 2, key: { _id: 1 }, name: '_id_' },
{ v: 2, key: { 'dob.age': 1 }, name: 'dob.age_1' }
]כפי שרואים, יש לנו כרגע שני אינדקסים. הראשון נוצר אוטומטית והוא אינדקס על השדה id_.
את השני אנחנו יצרנו על השדה dob.age.
הבנת פעולת האינדקסים
במקרים מסויימים האינדקס עלול לגרום לזמן השאילתא להתארך. למשל בשאילתות שמחזירות את כל המסמכים או את רובם הגדול.
נראה דוגמה ולאחר מכן נסביר למה זה קורה.
נבדוק כמה לקוחות יש מעל גיל 20:
clients> db.contacts.find({"dob.age": {$gt: 20}}).count()
5000אנחנו רואים שזה כל הלקוחות.
נבדוק כמה זמן לוקחת לנו שאילתא של מציאת כל הלקוחות מעל גיל 20 ללא אינדקס על dob.age:
clients> db.contacts.explain("executionStats").find({"dob.age": {$gt: 20}}) { explainVersion: '1', queryPlanner: { namespace: 'clients.contacts', indexFilterSet: false, parsedQuery: { 'dob.age': { '$gt': 20 } }, queryHash: '08155E45', planCacheKey: '08155E45', maxIndexedOrSolutionsReached: false, maxIndexedAndSolutionsReached: false, maxScansToExplodeReached: false, winningPlan: { stage: 'COLLSCAN', filter: { 'dob.age': { '$gt': 20 } }, direction: 'forward' }, rejectedPlans: [] }, executionStats: { executionSuccess: true, nReturned: 5000, executionTimeMillis: 4, … }
הזמן שנדרש לשאילתא הזו הוא 4ms.
עכשיו נוסיף אינדקס:
clients> db.contacts.createIndex({"dob.age": 1})
dob.age_1ונבדוק את אותה שאילתא עם אינדקס:
clients> db.contacts.explain("executionStats").find({"dob.age": {$gt: 20}}) { explainVersion: '1', queryPlanner: { namespace: 'clients.contacts', indexFilterSet: false, parsedQuery: { 'dob.age': { '$gt': 20 } }, queryHash: '08155E45', planCacheKey: '3F4F0F60', maxIndexedOrSolutionsReached: false, maxIndexedAndSolutionsReached: false, maxScansToExplodeReached: false, winningPlan: { stage: 'FETCH', inputStage: { stage: 'IXSCAN', keyPattern: { 'dob.age': 1 }, indexName: 'dob.age_1', isMultiKey: false, multiKeyPaths: { 'dob.age': [] }, isUnique: false, isSparse: false, isPartial: false, indexVersion: 2, direction: 'forward', indexBounds: { 'dob.age': [ '(20, inf.0]' ] } } }, rejectedPlans: [] }, executionStats: { executionSuccess: true, nReturned: 5000, executionTimeMillis: 13, … }
רואים שהזמן שנדרש עכשיו לשאילתא הזו הוא 13ms.
אז במקרה הזה האינדקס גרם לשאילתא לקחת יותר זמן.
הסיבה לכך היא שהאינדקס מוסיף עוד צעד לשאילתא. קודם כל מונגו יעבור על האינדקסים וימצא את ה-keys הנכונים ולאחר מכן יביא כל מסמך ע"י הפוינטר שלו.
לעומת זאת, במקרה שאין אינדקס, השאילתא תביא כל מסמך שהיא מוצאת ומתאים לשאילתא שלנו ואז בצעד אחד אנחנו מקבלים כל מסמך ולא בשני צעדים. אמנם הצעד של החזרת ה-keys הוא צעד מהיר יחסית, אבל בשאילתות שאנחנו בכל מקרה מביאים את כל המסמכים יוצא שהאינדקס לא חסך לנו כלום אלא רק הוסיף עוד עבודה.
אם חוזרים רק חלק מהמסמכים, אז האינדקס יכול לעזור לנו מאוד בכך שלא נעבור על כל המסמכים אלא רק על חלק מהם, ואולי אפילו רק על חלק קטן מהם ואז האינדקס יהיה מאוד יעיל.
אבל אם מחזירים את כל המסמכים או את רובם הגדול האינדקס הוא לא יעיל ולפעמים גם פוגע.
אינדקסים מורכבים - compound indexes
אינדקס מורכב הוא אינדקס על מספר שדות. למשל, במקום ליצור אינדקס רק על הגיל, ניצור אותו על הגיל והמין:
clients> db.contacts.createIndex({"dob.age": 1, gender: 1})
dob.age_1_gender_1במקרה הזה האינדקס נוצר בצורה ממוינת קודם לפי הגיל ואת כל המסמכים עם אותו גיל ממיין לפי המין.
לכן, אם נחפש עם סינון רק לפי גיל, האינדקס הזה יעזור לנו. כמובן שאם נחפש עם סינון לפי גיל ומין גם אז האינדקס יעזור לנו.
אבל אם נחפש עם סינון רק לפי מין האינדקס הזה לא יעזור לנו ומונגו לא ישתמש בו.
נראה דוגמאות. נחפש רק לפי גיל:
clients> db.contacts.explain("executionStats").find({"dob.age": {$gt: 50}}) { explainVersion: '1', queryPlanner: { namespace: 'clients.contacts', indexFilterSet: false, parsedQuery: { 'dob.age': { '$gt': 50 } }, queryHash: '08155E45', planCacheKey: '3F4F0F60', maxIndexedOrSolutionsReached: false, maxIndexedAndSolutionsReached: false, maxScansToExplodeReached: false, winningPlan: { stage: 'FETCH', inputStage: { stage: 'IXSCAN', keyPattern: { 'dob.age': 1, gender: 1 }, indexName: 'dob.age_1_gender_1', …
רואים שמונגו עשה שימוש באינדקס.
נחפש לפי גיל ומין:
clients> db.contacts.explain("executionStats").find({"dob.age": {$gt:50}, gender: "male"}) { explainVersion: '1', queryPlanner: { namespace: 'clients.contacts', indexFilterSet: false, parsedQuery: { '$and': [ { gender: { '$eq': 'male' } }, { 'dob.age': { '$gt': 50 } } ] }, queryHash: '137510FD', planCacheKey: '0EA086F8', maxIndexedOrSolutionsReached: false, maxIndexedAndSolutionsReached: false, maxScansToExplodeReached: false, winningPlan: { stage: 'FETCH', inputStage: { stage: 'IXSCAN', keyPattern: { 'dob.age': 1, gender: 1 }, indexName: 'dob.age_1_gender_1', …
שוב נעשה שימוש באינדקס.
אבל אם נחפש רק לפי מין:
clients> db.contacts.explain("executionStats").find({gender: "male"}) { explainVersion: '1', queryPlanner: { namespace: 'clients.contacts', indexFilterSet: false, parsedQuery: { gender: { '$eq': 'male' } }, queryHash: '025F03D3', planCacheKey: '4B09AA47', maxIndexedOrSolutionsReached: false, maxIndexedAndSolutionsReached: false, maxScansToExplodeReached: false, winningPlan: { stage: 'COLLSCAN', filter: { gender: { '$eq': 'male' } }, direction: 'forward' }, rejectedPlans: [] },
רואים שלא נעשה שימוש באינדקס וה-plan שבו השתמש מונגו הוא COLLSCAN.
שיפור הפקודה sort בעזרת אינדקס
כשיש לנו אינדקס על שדה מסוים ואנו משתמשים בפקודה sort על אותו שדה, יש מקרים שבהם מונגו יוכל להשתמש באינדקס כדי לשפר את המהירות שבה sort מתבצע כיון שהאינדקס כבר מכיל את המידע ממוין.
למשל, אם יש לנו את האינדקס מהדוגמה הקודמת ועכשיו נבצע את הפקודה הבאה:
clients> db.contacts.explain().find({"dob.age": 41}).sort({gender: 1}) { explainVersion: '1', queryPlanner: { namespace: 'clients.contacts', indexFilterSet: false, parsedQuery: { 'dob.age': { '$eq': 41 } }, queryHash: '5EAC5FEC', planCacheKey: '8FF2E917', maxIndexedOrSolutionsReached: false, maxIndexedAndSolutionsReached: false, maxScansToExplodeReached: false, winningPlan: { stage: 'FETCH', inputStage: { stage: 'IXSCAN', keyPattern: { 'dob.age': 1, gender: 1 }, indexName: 'dob.age_1_gender_1', isMultiKey: false, multiKeyPaths: { 'dob.age': [], gender: [] }, isUnique: false, isSparse: false, isPartial: false, indexVersion: 2, direction: 'forward', indexBounds: { 'dob.age': [ '[41, 41]' ], gender: [ '[MinKey, MaxKey]' ] } } }, rejectedPlans: [] }, …
נוכל לראות שמונגו השתמש ב-'IXSCAN' לצורך ביצוע המשימה והוא עשה את זה גם עבור age שעליו ביצענו את ה-find אבל גם עבור gender שעליו ביצענו את ה-sort.
צריך לדעת שלמונגו יש 32MB בזיכרון שמיועדים למיון. אם אין לנו אינדקס עבור השדה שלפיו רוצים למיין אז מונגו יעתיק את כל המידע שהוא מצא ב-find לתוך הזיכרון הזה ויבצע שם את המיון.
במקרה שבו ה-find החזיר לנו מספר רב של מסמכים יכול להיות שמונגו בכלל לא יוכל לבצע את המיון בזיכרון של 32MB, ולכן במקרה הזה האינדקס לא רק משפר את מהירות המיון אלא מאפשר את המיון ובלעדיו לא ניתן יהיה למיין.
שימוש באינדקס לקנפג שדה ייחודי (unique)
כשיוצרים אינדקס ניתן בעזרתו לקנפג את אותו השדה שיהיה גם unique.
למשל, אם אנחנו רוצים ליצור אינדקס ייחודי על השדה phone נעשה זאת כך:
clients> db.contacts.createIndex({phone: 1}, {unique: true})
phone_1עכשיו לא יהיה ניתן להכניס מסמך עם phone זהה למסמך אחר.
אם ננסה ליצור אינדקס ייחודי לשדה שכבר עכשיו יש בו כפילויות נקבל שגיאה. למשל ננסה לעשות את זה על השדה email:
clients> db.contacts.createIndex({email: 1}, {unique: true})
MongoServerError: Index build failed: 2054a4c0-5cad-44cc-a950-d817ff156f4f: Collection
clients.contacts ( 6da89c84-08bb-4235-9a4c-c20505d9a2bc ) :: caused by :: E11000 duplicate
key error collection: clients.contacts index: email_1 dup key:
{ email: "abigail.clark@example.com" }כפי שרואים, קיבלנו שגיאה שיש כבר עכשיו יותר ממסמך אחד שיש בו email עם הערך abigail.clark@example.com.
אינדקס חלקי - Partial index
ניתן ליצור אינדקס כך שיחול רק על חלק מהערכים.
למשל, במקום לעשות אינדקס על כל הערכים האפשריים של age נוכל לעשות אינדקס רק כאשר הערך גדול מ-50:
clients> db.contacts.createIndex(
{"dob.age": 1}, {partialFilterExpression: {"dob.age": {$gt: 50}}})
dob.age_1למה בעצם צריך דבר כזה?
אם אנחנו יודעים שהשאילתות שלנו יהיו בעיקר כשה-age הוא גדול מ-50 לפעמים כדאי ליצור דווקא אינדקס חלקי. היתרון שלו הוא בכך שהוא תופס פחות מקום בדיסק, ובנוסף בגלל שהאינדקס חל על פחות ערכים לכן הביצועים שלו יהיו יותר טובים בשאילתות שחלות על הערכים שהאינדקס שייך אליהם.
שני היתרונות האלו באים לידי ביטוי כשכמות הנתונים שלנו גדולה ואז נוכל לראות שיפור משמעותי בגודל הזיכרון בדיסק שהאינדקס צורך וכן במהירות שבה נקבל תשובות לשאילתות שלנו.
כמובן שאם ניצור שאילתא על ערכים שלא כלולים באינדקס שיצרנו אז מונגו לא ישתמש באינדקס הזה, כי הדבר הכי חשוב למונגו זה להחזיר לנו את כל המסמכים לשאילתא שלנו בצורה מדוייקת בלי לפספס שום מסמך.
אפשרות נוספת היא ליצור אינדקס שחל על כל ערך של age אבל רק כאשר באותו מסמך השדה gender שווה ל-male.
תחילה נמחוק את האינדקס שיצרנו (אם לא נעשה את זה נקבל שגיאה כשננסה ליצור את האינדקס החדש, כיון שאנחנו לא מציינים את שם האינדקס החדש, הוא יתן לו שם אוטומטי שכבר קיים):
clients> db.contacts.dropIndex(
{"dob.age": 1}, {partialFilterExpression: {"dob.age": {$gt: 50}}})
{ nIndexesWas: 2, ok: 1 }ולאחר מכן ניצור את האינדקס החדש:
clients> db.contacts.createIndex(
{"dob.age": 1}, {partialFilterExpression: {gender: "male"}})
dob.age_1אינדקס חלקי כפתרון לבעיית אינדקס ייחודי
ישנה בעיה מעניינת במונגו כשיוצרים אינדקס ייחודי לשדה מסוים אבל לחלק מהמסמכים אין את השדה הזה. במקרה הזה, מונגו מתייחס לכל מסמך שאין את השדה הזה כאילו יש לו את השדה הזה אבל עם ערך של null ולכן אם יש לנו מסמך אחד ללא השדה הזה, לא נוכל ליצור מסמך נוסף ללא השדה הזה כי אז מונגו יוסיף לו את השדה הזה עם ערך null וכיון שקיימים כבר מסמכים עם אותו הערך לא ניתן ליצור עוד אחד עם ערך זהה כי השדה צריך להיות ייחודי.
נראה דוגמה לבעיה הזו, ולאחר מכן נראה איך אינדקס חלקי פותר לנו את הבעיה.
students> db.students.insertMany([{name: "Rafael", email: "rafraph@gmail.com"}, {name: "Nadav"}])
{
acknowledged: true,
insertedIds: {
'0': ObjectId("64ff105350315e76714b5f80"),
'1': ObjectId("64ff105350315e76714b5f81")
}
}
students> db.students.createIndex({email: 1}, {unique: true})
email_1
students> db.students.insertOne({name: "David"})
MongoServerError: E11000 duplicate key error collection: students.students
index: email_1 dup key: { email: null }- בפקודה הראשונה יצרנו שני מסמכים. אחד עם שם ואימייל והשני רק עם שם.
- בפקודה השניה, יצרנו אינדקס ייחודי על האימייל.
- בפקודה השלישית הכנסנו מסמך חדש רק עם שם וקיבלנו שגיאה.
כמו שהסברתי לעיל, השגיאה נובעת מכך שיש לנו אינדקס ייחודי על האימייל ועכשיו אני מנסה להכניס מסמך חדש ללא אימייל שזה בעצם אומר שהשדה אימייל מוגדר כ-null. וכיון שכבר יש לנו מסמך אחד ללא אימייל לכן הערך null הוא כבר לא ייחודי ולכן קיבלנו שגיאה.
הפתרון לכך הוא ע"י יצירת אינדקס חלקי שיווצר רק למסמכים שבהם השדה של האימייל קיים.
נתחיל במחיקת האינדקס:
students> db.students.dropIndex({email: 1})עכשיו ניצור את האינדקס החלקי:
students> db.students.createIndex({email: 1},
{unique: true, partialFilterExpression: {email: {$exists: true}}})
email_1וננסה שוב להכניס משתמש ללא אימייל:
students> db.students.insertOne({name: "David"})
{
acknowledged: true,
insertedId: ObjectId("64ff120050315e76714b5f83")
}עכשיו הפעולה הצליחה, וזה בזכות האינדקס החלקי.
אינדקס עם TTL - Time To Live
ניתן להגדיר אינדקס על שדות מסוג date כך שלאחר זמן מסוים המסמך עם השדה הזה ימחק מה-DB.
נדגים זאת ע"י דוגמה. נתחיל מקולקשיין ריק ונכניס מסמך הכולל שדה מסוג Date.
students> db.students.insertOne({name: "Rafael", createdAt: new Date()})
{
acknowledged: true,
insertedId: ObjectId("65000ecf50315e76714b5f84")
}השדה createdAt מכיל את הזמן והתאריך הנוכחי.
ניצור אינדקס עם TTL:
students> db.students.createIndex({createdAt: 1}, {expireAfterSeconds: 10})
createdAt_1האינדקס הזה מוגדר כך שמסמכים עם createdAt ימחקו אחרי 10 שניות. בפועל זמן המחיקה הוא לא מובטח. מונגו מריץ ג'וב שמוחק את המסמכים כל 60 שניות ולכן יכול להיות עד 60 שניות הבדל בין זמן המחיקה המבוקש לזמן המחיקה בפועל.
ולכן נחכה בין 10 ל-70 שניות ולאחר מכן נבדוק את הקולקשיין ונראה שהמסמך נמחק.
יש לציין שהאפשרות הזאת זמינה רק עבור שדות מסוג date ורק לאינדקסים על שדה אחד ולא על אינדקסים מורכבים שכוללים יותר משדה אחד.
מהו covered query?
זוהי שאילתא שיש אינדקס שיכול לענות עליה גם בלי לבדוק שום מסמך. ההוכחה לכך היא שפקודת explain תראה לנו totalDocsExamined: 0.
נראה דוגמה שתעזור לנו להבין את זה.
נניח שה-DB של students ריק ואני מכניס אליו שני מסמכים:
students> db.students.insertMany([{name: "Rafael", age: 42}, {name: "Aharon", age: 30}])
{
acknowledged: true,
insertedIds: {
'0': ObjectId("6664f2462235e7545e1f2a53"),
'1': ObjectId("6664f2462235e7545e1f2a54")
}
}ניצור אינדקס לפי שם:
students> db.students.createIndex({name: 1})
name_1עכשיו אנסה לחפש מסמך של סטודנט עם השם אהרון:
students> db.students.explain("executionStats").find({name: "Aharon"}) { explainVersion: '1', queryPlanner: { namespace: 'students.students', indexFilterSet: false, parsedQuery: { name: { '$eq': 'Aharon' } }, queryHash: '64908032', planCacheKey: '39E6C6F3', maxIndexedOrSolutionsReached: false, maxIndexedAndSolutionsReached: false, maxScansToExplodeReached: false, winningPlan: { stage: 'FETCH', inputStage: { stage: 'IXSCAN', keyPattern: { name: 1 }, indexName: 'name_1', isMultiKey: false, multiKeyPaths: { name: [] }, isUnique: false, isSparse: false, isPartial: false, indexVersion: 2, direction: 'forward', indexBounds: { name: [ '["Aharon", "Aharon"]' ] } } }, rejectedPlans: [] }, executionStats: { executionSuccess: true, nReturned: 1, executionTimeMillis: 1, totalKeysExamined: 1, totalDocsExamined: 1, executionStages: { stage: 'FETCH', nReturned: 1, executionTimeMillisEstimate: 0, works: 2, advanced: 1, needTime: 0, needYield: 0, saveState: 0, restoreState: 0, isEOF: 1, docsExamined: 1, alreadyHasObj: 0, inputStage: { stage: 'IXSCAN', nReturned: 1, executionTimeMillisEstimate: 0, …
ניתן לראות כאן שהשיטה שבה מונגו השתמש כדי למצוא את המסמכים היא 'IXSCAN'. בנוסף רואים שמסמך אחד חזר, ומסמך אחד נסרק:
nReturned: 1,
…
totalDocsExamined: 1,
אז איך בעצם ניתן להגיע ל-totalDocsExamined שווה לאפס?
זה אפשרי אם המידע שאנחנו מחפשים הוא המידע שהאינדקס מחזיק. במקרה שלנו השדה name. אם למשל נחפש רק את name ובמפורש נבקש לא להחזיר את השדה id_, בצורה הבאה:
students> db.students.explain("executionStats").find({name: "Aharon"}, {_id: 0, name: 1}) { explainVersion: '1', queryPlanner: { namespace: 'students.students', indexFilterSet: false, parsedQuery: { name: { '$eq': 'Aharon' } }, queryHash: '4B1D5B79', planCacheKey: 'A0802703', maxIndexedOrSolutionsReached: false, maxIndexedAndSolutionsReached: false, maxScansToExplodeReached: false, winningPlan: { stage: 'PROJECTION_COVERED', transformBy: { _id: 0, name: 1 }, inputStage: { stage: 'IXSCAN', keyPattern: { name: 1 }, indexName: 'name_1', isMultiKey: false, multiKeyPaths: { name: [] }, isUnique: false, isSparse: false, isPartial: false, indexVersion: 2, direction: 'forward', indexBounds: { name: [ '["Aharon", "Aharon"]' ] } } }, rejectedPlans: [] }, executionStats: { executionSuccess: true, nReturned: 1, executionTimeMillis: 0, totalKeysExamined: 1, totalDocsExamined: 0, executionStages: { stage: 'PROJECTION_COVERED', nReturned: 1, executionTimeMillisEstimate: 0, works: 2, advanced: 1, needTime: 0, needYield: 0, saveState: 0, restoreState: 0, isEOF: 1, transformBy: { _id: 0, name: 1 }, inputStage: { stage: 'IXSCAN', nReturned: 1, executionTimeMillisEstimate: 0, … }, …
כפי שרואים, במקרה הזה totalDocsExamined: 0. לשאילתא כזו קוראים covered query והיא יעילה מאוד. כמובן שרוב השאילתות לא כאלו. אבל כדאי להכיר את האפשרות הזו וכשיש לנו שאילתא שאנו יכולים להפוך אותה ל-covered query כדאי לעשות זאת ועל ידי כך לשפר ביצועים.
איך מונגו בוחר את שיטת החיפוש - plan?
בפקודת explain מונגו מדווח לנו מה ה-plan שהוא השתמש בו (תחת השדה winningPlan) ומה ה-plans שהוא דחה (תחת השדה rejectedPlans).
למשל אם יש לי כמה אינדקסים, הוא יבדוק את האינדקסים הרלוונטים וידווח לנו באיזה מהם הוא השתמש, ואיזה הוא בדק והחליט לא להשתמש.
איך מונגו בודק ומחליט במה להשתמש?
הוא מתחיל בכך שהוא מזהה איזה אינדקסים יכולים להיות רלוונטים. למשל אם חיפשתי לפי השדה name ויש לי אינדקס על name וגם אינדקס מורכב לפי name, age שניהם יבדקו.
לאחר מכן הוא בודק את כל ה-plans שהוא החליט שיכולים להיות רלוונטים. הוא מריץ אותם על חלק מהמידע ובודק מי הכי מהיר. נכון להיום הבדיקה היא על 100 documents. ה-plan המנצח בבדיקה הזו - יהיה ה-plan שבו מונגו ישתמש.
הבדיקה הזו לוקחת זמן, לכן מונגו לא עושה אותה כל שאילתא. הוא שומר ב-cache את ה-winning plan יחד עם השאילתא שנבדקה, ואם השאילתא שוב תגיע הוא ישתמש ב-winning plan שהוא שמר.
ה-cache הזה נשמר ב-DB עד אחד מהמקרים הבאים:
- אם נעשה restart לשרת של מונגו
- נכתבו 1000 מסמכים לקולקשיין המדובר
- אם האינדקס שבו משתמש ה-winning plan נמחק
- אם נוספו אינדקסים חדשים
כדי לראות את כל הפרטים והאנליזות על כל ה-plans שנבדקו אפשר להשתמש ב-allPlansExecution בפקודת explain בצורה הבא:
students> db.students.explain("allPlansExecution").find({name: "Aharon"},
{_id: 0, name: 1})אינדקס מסוג multi-key
עד עכשיו עסקנו באינדקסים על שדות שאינם מערכים. ניתן ליצור אינדקס גם לשדות מסוג מערך. אינדקס כזה יהיה אוטומטית מסוג multi-key.
נסביר את הסיבה לשם הזה. כשמונגו יוצר את האינדקס עבור שדה שהוא מערך הוא בעצם לוקח את כל הערכים במערך ומאנדקס אותם. אם עכשיו נוסיף עוד מסמך שיש בו ערכים אחרים למערך שמאונדקס, הוא יוסיף גם אותם לאינדוקס.
מובן מכאן שאינדקסים כאלה עלולים לתפוס הרבה זיכרון. אם למשל יש לנו 1000 מסמכים ואנחנו יוצרים אינדקס על שדה של מערך שמכיל בממוצע 3 ערכים שונים בכל מסמך, נקבל אינדקס שיש בו 3000 רשומות.
נראה דוגמה:
נכניס ל-students את המסמך הבא:
students> db.students.insertOne({name: "Orit", age: 36, kids: ["Reuven", "Shimon", "Levi"]})
וניצור אינדקס עבור kids:
students> db.students.createIndex({kids: 1})
kids_1עכשיו נבצע חיפוש לכל הסטודנטים שיש להם ילד בשם לוי:
students> db.students.explain("executionStats").find({kids: "Levi"}) { explainVersion: '1', queryPlanner: { namespace: 'students.students', indexFilterSet: false, parsedQuery: { kids: { '$eq': 'Levi' } }, queryHash: '8EAA114C', planCacheKey: '2AC4C135', maxIndexedOrSolutionsReached: false, maxIndexedAndSolutionsReached: false, maxScansToExplodeReached: false, winningPlan: { stage: 'FETCH', inputStage: { stage: 'IXSCAN', keyPattern: { kids: 1 }, indexName: 'kids_1', isMultiKey: true, multiKeyPaths: { kids: [ 'kids' ] }, isUnique: false, isSparse: false, isPartial: false, indexVersion: 2, direction: 'forward', indexBounds: { kids: [ '["Levi", "Levi"]' ] } } }, …
כפי שניתן לראות מונגו השתמש באינדקס שיצרנו וסימן אותו כ- isMultiKey: true.
מקרה מורכב יותר הוא כאשר יש לנו שדה של מערך ובתוכו יש אובייקטים. נוסיף שדה כזה למסמך שלנו:
students> db.students.updateOne({name: "Orit"},{$set:{cars: [{company: "Toyota", year: 2010}, {company: "Honda", year: 2015}]}})
students> db.students.find({name: "Orit"})
[
{
_id: ObjectId("66658fef2235e7545e1f2a55"),
name: 'Orit',
age: 36,
kids: [ 'Reuven', 'Shimon', 'Levi' ],
cars: [
{ company: 'Toyota', year: 2010 },
{ company: 'Honda', year: 2015 }
]
}
]הוספנו לאורית מערך של מכוניות, שלכל אחת יש שם חברה ושנת ייצור.
ניצור אינדקס לשדה cars:
students> db.students.createIndex({cars: 1})ונבדוק שאילתא לפי שנת ייצור של מכונית:
students> db.students.explain("executionStats").find({"cars.year": 2010}) { explainVersion: '1', queryPlanner: { namespace: 'students.students', indexFilterSet: false, parsedQuery: { 'cars.year': { '$eq': 2010 } }, queryHash: 'DC003564', planCacheKey: 'ED0D68B7', maxIndexedOrSolutionsReached: false, maxIndexedAndSolutionsReached: false, maxScansToExplodeReached: false, winningPlan: { stage: 'COLLSCAN', filter: { 'cars.year': { '$eq': 2010 } }, direction: 'forward' }, …
כפי שרואים, מונגו השתמש בשיטת COLLSCAN (סריקה של כל הקולקשיין) ולא השתמש באינדקס שיצרנו.
הסיבה לכך היא שכאשר מונגו יוצר אינדקס מסוג multi-key הוא מחלץ את כל האיברים של המערך ומאנדקס אותם אבל הוא לא הולך יותר לעומק ומחלץ מכל איבר את השדות שלו.
במקרה שלנו הוא לא יאנדקס את השדות company ו-year שיש לכל איבר בשדה של cars. אלא יאנדקס את cars לפי אובייקטים. ולכן אם נעשה שאילתא על השדה cars מונגו אכן ישתמש באינדקס שלנו:
students> db.students.explain("executionStats").find({cars: {year: 2010}}) { explainVersion: '1', queryPlanner: { namespace: 'students.students', indexFilterSet: false, parsedQuery: { cars: { '$eq': { year: 2010 } } }, queryHash: '2E454BF8', planCacheKey: '57AB6D36', maxIndexedOrSolutionsReached: false, maxIndexedAndSolutionsReached: false, maxScansToExplodeReached: false, winningPlan: { stage: 'FETCH', inputStage: { stage: 'IXSCAN', keyPattern: { cars: 1 }, indexName: 'cars_1', isMultiKey: true, multiKeyPaths: { cars: [ 'cars' ] }, isUnique: false, isSparse: false, isPartial: false, indexVersion: 2, direction: 'forward', indexBounds: { cars: [ '[{ year: 2010 }, { year: 2010 }]' ] } } }, …
כפי שרואים, מונגו השתמש באינדקס cars_1.
ניתן גם ליצור אינדקס על איבר בתוך שדה של מערך. למשל במקרה שלנו, אפשר ליצור אינדקס על cars.year:
students> db.students.createIndex({"cars.year": 1})
cars.year_1ואז עבור השאילתא הקודמת שמונגו לא השתמש עבורה בשום אינדקס:
students> db.students.explain("executionStats").find({"cars.year": 2010})
עכשיו הוא אכן ישתמש באינדקס הזה.
שוב נזכיר שצריך להיזהר עם זה כי אינדקס כזה יכול לגרום לבעיות בביצועים אם הוא הופך להיות גדול.
ניתן גם ליצור אינדקס מורכב, compound index, עבור שדה רגיל ושדה שהוא מערך.
לדוגמה:
students> db.students.createIndex({name:1, cars: 1})
name_1_cars_1אבל לא ניתן ליצור אינדקס מורכב עבור יותר משדה אחד שהוא מערך. לדוגמה:
students> db.students.createIndex({kids:1, cars: 1}) MongoServerError: Index build failed: 404a9053-5ada-4c4a-9b2e-fcee20a6b960: Collection students.students ( 15fb1e9a-8510-4f9c-a398-807d78b2bc80 ) :: caused by :: cannot index parallel arrays [cars] [kids]
ההיגיון הוא שעבור אינדקס שיש בו יותר משדה אחד שהוא מערך, מונגו יצטרך לאנדקס כל איבר בכל מערך מול כל איבר במערך השני, והדרך הזו מובילה במהירות לאינדקסים גדולים מדיי. למשל שני שדות של מערך שבכל אחד יש 100 אפשרויות יגרמו ליצירת אינדקס על 10,000 רשומות. לכן מונגו לא תומך בזה.
אינדקס לשדות טקסט
ניתן ליצור אינדקסים לשדות שמכילים טקסט. אבל אם ניצור אותם בדרך הרגילה הם לא יהיו יעילים בד"כ.
אם למשל יש לי את המסמכים הבאים:
books> db.books.find()
[
{
_id: ObjectId("6666c4bc2235e7545e1f2a56"),
title: 'The Blocksize war',
description: 'This book covers Bitcoin’s blocksize war power'
},
{
_id: ObjectId("6666c52d2235e7545e1f2a57"),
title: 'Crack the Crypto Code',
description: 'Unlocking the Power of Cryptocurrency Arbitrage by yours truly, Alexander Webster'
}
]ואני אצור אינדקס בדרך הרגילה על השדה description:
books> db.books.createIndex({description: 1})
description_1האינדקס הזה יעזור לי רק במקרה שאחפש בדיוק את כל הטקסט שיש ב-description ולא אם אחפש מילה אחת מתוך כל הטקסט הזה. אינדקס כזה יעזור רק במקרים של שדות טקסט עם מילה אחת או שתיים כמו שם של אדם.
רוב הפעמים אני מעוניין לחפש מילה או ביטוי מתוך כל הטקסט, ולצורך כך יש אינדקס מסוג טקסט שניתן ליצור אותו בצורה הבאה:
books> db.books.createIndex({description: "text"})
description_textהאינדקס הזה לוקח את כל המילים החשובות (key words) שיש בשדה הזה ומכניס אותם למערך. הוא לא שומר מילות קישור כמו am, is, are, the כי הם מופיעות הרבה ולא מחפשים אותם בד"כ.
חיפוש הטקסט מתבצע באופן הבא:
books> db.books.find({$text: {$search: "power"}})
[
{
_id: ObjectId("6666c52d2235e7545e1f2a57"),
title: 'Crack the Crypto Code',
description: 'Unlocking the Power of Cryptocurrency Arbitrage by yours truly, Alexander Webster' }, { _id: ObjectId("6666c4bc2235e7545e1f2a56"), title: 'The Blocksize war', description: 'This book covers Bitcoin’s blocksize war power' } ]
כפי שניתן לראות, אנחנו לא מציינים באיזה שדה לחפש. האמת שלא ניתן לקבוע שדה שבו מחפשים. החיפוש יתבצע בכל שדות הטקסט שלהם נוצר האינדקס.
הסיבה לכך היא שאינדקס טקסט בד"כ דורש הרבה מקום כדי להכניס כל מילה ולכן מונגו מאפשר רק טקסט אינדקס אחד עבור כל הקולקשיין. מצד שני, האינדקס שיצרנו מאנדקס את הטקסט רק של השדות שביקשנו ליצור להם אינדקס טקסט, אבל כל הטקסט שנאנדקס יכנס לאותו אינדקס.
כרגע האינדקס שלנו הוא רק עבור השדה description, עוד מעט נראה איך מוסיפים שדות טקסט אחרים לאינדקס הזה.
החיפוש הוא incase sensitive. אם רוצים שהוא יהיה case sensitive אפשר להוסיף את הפרמטר הזה באופן הבא:
books> db.books.find({$text: {$search: "power", $caseSensitive: true}})נחפש מילה שמופיעה רק באחד המסמכים:
books> db.books.find({$text: {$search: "bitcoin"}})
[
{
_id: ObjectId("6666c4bc2235e7545e1f2a56"),
title: 'The Blocksize war',
description: 'This book covers Bitcoin’s blocksize war power'
}
]עכשיו נחפש צירוף של שני מילים:
books> db.books.find({$text: {$search: "war power"}})
[
{
_id: ObjectId("6666c52d2235e7545e1f2a57"),
title: 'Crack the Crypto Code',
description: 'Unlocking the Power of Cryptocurrency Arbitrage by yours truly, Alexander Webster' }, { _id: ObjectId("6666c4bc2235e7545e1f2a56"), title: 'The Blocksize war', description: 'This book covers Bitcoin’s blocksize war power' } ]
למרות שהביטוי נמצא רק במסמך אחד מונגו החזיר את שני המסמכים וזה כיון שהוא מחפש כל מילה בנפרד. אם אנחנו רוצים לחפש ביטוי נוסיף גרשיים מסביב לביטוי יחד עם התו \ וזה בגלל שהטקסט כבר נמצא בתוך גרשיים:
books> db.books.find({$text: {$search: "\"war power\""}})
[
{
_id: ObjectId("6666c4bc2235e7545e1f2a56"),
title: 'The Blocksize war',
description: 'This book covers Bitcoin’s blocksize war power'
}
]כשחיפשנו צירוף (ולא ביטוי) של המילים war power ראינו שמונגו מחזיר את כל המסמכים שיש בהם לפחות מילה אחת מתוך שתי המילים. דווקא המסמך שבו קיים צירוף המילים האלו במדויק היה התוצאה השניה. לפעמים מאוד עוזר שמונגו מחזיר את התוצאות בצורה ממויינת לפי דירוג שהוא נותן לתוצאות וכך נקבל את התוצאות הטובות יותר ראשונות.
כדי למיין את התוצאות לפי הדירוג שלהם וגם לראות את הדירוג שלהם נשתמש בפקודה הבאה:
books> db.books.find({$text: {$search: "war power"}}, {score: {$meta: "textScore"}}).sort({score: {$meta: "textScore"}})[
{
_id: ObjectId("6666c4bc2235e7545e1f2a56"),
title: 'The Blocksize war',
description: 'This book covers Bitcoin’s blocksize war power',
score: 1.1428571428571428
},
{
_id: ObjectId("6666c52d2235e7545e1f2a57"),
title: 'Crack the Crypto Code',
description: 'Unlocking the Power of Cryptocurrency Arbitrage by yours truly, Alexander Webster', score: 0.5714285714285714 } ]
מקודם הזכרנו שניתן להכניס יותר משדה אחד לאינדקס טקסט. כדי לעשות את זה צריך מראש ליצור את האינדקס עבור כל השדות שאנו רוצים. לא ניתן להוסיף שדות לאינדקס קיים ולכן קודם נמחק את האינדקס ואז ניצור חדש.
נמצא קודם את שם האינדקס:
books> db.books.getIndexes()
[
{ v: 2, key: { _id: 1 }, name: '_id_' },
{
v: 2,
key: { _fts: 'text', _ftsx: 1 },
name: 'description_text',
weights: { description: 1 },
default_language: 'english',
language_override: 'language',
textIndexVersion: 3
}
]נמחק אותו ע"י שם האינדקס:
books> db.books.dropIndex('description_text') { nIndexesWas: 2, ok: 1 }
ועכשיו ניצור אינדקס חדש עבור title ו-description בצורה הבאה:
books> db.books.createIndex({title: "text", description: "text"})
title_text_description_textבחיפושי הטקסט שנעשה מעכשיו מונגו יחפש ב-title וגם ב-description.
אנחנו גם יכולים לתת משקל שונה לכל שדה, כך שאם יותר חשוב לנו שהמילה תופיע ב-title מאשר ב-description נוכל לתת לו משקל גדול יותר באופן הבא:
books> db.books.createIndex({title: "text", description: "text"},
{weights: {title: 5, description: 1}})באופן הזה מונגו יתן משקל גדול פי 5 למילים שנמצאו ב-title לעומת מילים שנמצאו ב-description.
בפקודת החיפוש ניתן גם להגדיר שלא יחזרו תוצאות שיש בהם טקסט מסוים. עושים את זה פשוט ע"י הוספת מינוס לפני הטקסט שאנחנו רוצים שלא יופיע. למשל אם אנחנו רוצים לחפש את המילה power אבל לא מעוניינים בתוצאות עם המילה bitcoin נשתמש בפקודה:
books> db.books.find({$text: {$search: "power -bitcoin"}})
[
{
_id: ObjectId("6666c52d2235e7545e1f2a57"),
title: 'Crack the Crypto Code',
description: 'Unlocking the Power of Cryptocurrency Arbitrage by yours truly, Alexander Webster'
}
]הגדרת שפה לחיפושי טקסטים
חשוב לקבוע את שפת ברירת המחדל שבה נחפש טקסט כיון שלפי השפה מונגו יודע איך למצוא את השורש של המילה (להוריד אותיות שהם תחיליות וסופיות למילה) וכך למשל המילים running, runs, runner ימצאו כולם בחיפוש של המילה run . וכן לפי השפה הוא יודע איזה מילות קישור לא לאנדקס כדי לאפשר חיפוש טוב יותר.
השפה הדיפולטיבית של מונגו היא אנגלית. כדי לשנות אותה למשל לרוסית נוסיף ביצירת האינדקס את המידע הזה בצורה הבאה:
books> db.books.createIndex({title: "text", description: "text"}, {default_language: "russian"})את רשימת השפות הנתמכות במונגו אפשר לראות כאן. לצערנו עברית עדיין לא נתמכת.
פרק 9: שימוש מתקדם בעזרת aggregation framework
עד עכשיו השתמשנו הרבה בפקודת find כדי לחפש מסמכים. אבל לפעמים אנחנו מעוניינים לקבל את המידע באופן שונה ממה שיש ב-DB. למשל לפעמים יש צורך למיין את המידע ואז לסדר אותו לפי קבוצות מסוימות ומהם לחלץ רק מידע מסוים.
אפשר כמובן לקבל את כל המידע מה-DB ואז בקוד התוכנה שלנו לסדר את המידע אבל מונגו מאפשר לנו מראש לקבל את המידע בצורה שאנחנו רוצים. הדרך לעשות את זה היא ע"י יצירה של שרשרת פקודות (flow) שהמידע עובר עד שהוא מגיע אלינו. ה-aggregation framework הוא הכלי שמאפשר לנו ליצור את ה-flow הזה.
לצורך הלימוד נשתמש בנתונים שנמצאים בקובץ הזה (השתמשנו בקובץ זה גם בפרק קודם רק שהפעם יצרנו DB בשם שונה):
https://github.com/rafraph/filesForLearning/blob/main/persons.json
תורידו אותו למחשב שלכם, ואז כנסו לטרמינל במיקום שבו הקובץ נמצא. כדי לייבא את הנתונים לתוך מונגו נשתמש בפקודה הבאה:
C:\Users\rafael\Downloads>mongoimport persons.json -d persons -c persons --jsonArray 2024-06-16T12:22:03.744+0300 connected to: mongodb://localhost/ 2024-06-16T12:22:03.925+0300 5000 document(s) imported successfully.
0 document(s) failed to import.
עכשיו נחזור לטרמינל של mongosh וע"י הפקודה show dbs נוודא שיש לנו DB שנקרא persons.
כדי להשתמש בו נכתוב:
test> use persons switched to db persons
נבדוק איזה קולקשיינים יש לנו בתוכו:
persons> show collections persons
כדי להכיר את השדות של המסמכים, נראה דוגמה למסמך אחד שיש בקולקשיין:
persons> db.persons.findOne()
{
_id: ObjectId("666eaebb98bc901c0f6cb091"),
gender: 'female',
name: { title: 'ms', first: 'louise', last: 'graham' },
location: {
street: '5108 south street',
city: 'cashel',
state: 'galway',
postcode: 45802,
coordinates: { latitude: '35.5726', longitude: '148.0944' },
timezone: { offset: '+2:00', description: 'Kaliningrad, South Africa' }
},
email: 'louise.graham@example.com',
login: {
uuid: '062c592e-c6eb-44c3-beda-fb71e9c13bba',
username: 'whitekoala325',
password: 'harry',
salt: 'OjIRb3hP',
md5: 'fc32be9814936026c62bb21bb4a029cd',
sha1: '6350de80d1be4af1e7b2a498962f69993082126c',
sha256: 'abc804d7d87f0fd1a058b8db7acdf1d62e0b80412e282c427173c466040b29d1'
},
dob: { date: '1971-01-21T20:36:16Z', age: 47 },
registered: { date: '2002-10-19T17:05:42Z', age: 15 },
phone: '011-434-7405',
cell: '081-010-7792',
id: { name: 'PPS', value: '9774048T' },
picture: {
large: 'https://randomuser.me/api/portraits/women/59.jpg',
medium: 'https://randomuser.me/api/portraits/med/women/59.jpg',
thumbnail: 'https://randomuser.me/api/portraits/thumb/women/59.jpg'
},
nat: 'IE'
}שימוש ב-aggregate
נתחיל בשימוש ב-aggregate כדי ליצור פקודה זהה לפקודה find. נחפש את כל הגברים בקולקשיין:
persons> db.persons.aggregate([
... {$match: {gender: "male"}}
... ])- הפקודה הזו מקבלת מערך של פעולות (שנקראים stages) שיתבצעו על ה-documents לפי סדר.
- כל stage מתחיל עם סימן $.
- כל stage הוא אובייקט עם שדה אחד
- שם השדה הוא הפעולה והערכים הם הפירוט של מה שהפעולה תבצע.
- ה-stage הראשון מקבל את כל הנתונים מהקולקשיין. לאחר מכן, כל stage יקבל את הנתונים שנשארו מה-stage הקודם
במקרה הזה יש לנו רק stage אחד עם פקודת match שהיא זהה לפקודה find.
שימו לב שפקודת aggregate מחזירה לנו cursor.
הערה: כדי שיהיה יותר קל להבין את הפקודות, נכתוב אותם על פני כמה שורות כדי שה-stages יהיו ברורים (אגב, כדי לרדת שורה ב-mongosh בלי שהפקודה תתבצע אפשר פשוט ללחוץ enter כל עוד הפקודה לא מוכנה עם כל הסוגריים הסופיים שלה. כשעושים את זה mongosh מוסיף שלוש נקודות בתחילת כל שורה חדשה).
יצירת flow פשוט
כדי לראות את היתרון של aggregate נתחיל עם flow פשוט.
אנחנו רוצים:
- למצוא את כל הגברים בקולקשיין
- לקבל רק את השם, האימייל והגיל שלהם
- למיין אותם לפי גיל מהגבוה לנמוך
- לקבל רק את שלושת הראשונים
persons> db.persons.aggregate([{
... "$match": {gender: "male"}
... },{
... "$project": {
... "name": 1,
... "email": 1,
... "dob.age": 1,
... "_id": 0,
... }
... }, {
... "$sort": {"dob.age": -1}
... }, {
... "$limit": 3
... }]);
[
{
name: { title: 'mr', first: 'dieter', last: 'porto' },
email: 'dieter.porto@example.com',
dob: { age: 73 }
},
{
name: { title: 'mr', first: 'rayan', last: 'bonnet' },
email: 'rayan.bonnet@example.com',
dob: { age: 73 }
},
{
name: { title: 'mr', first: 'virgil', last: 'gonzales' },
email: 'virgil.gonzales@example.com',
dob: { age: 73 }
}
]- ה-stage הראשון הוא ה-match שיעביר הלאה רק documents שמתאימים לערך שלו. במקרה הזה רק גברים.
- ה-stage השני הוא ה-project. והוא יסיר מהתוצאות שהגיעו אליו את כל השדות שהם לא name או email או dob.age. ובנוסף הוא יסיר גם את id_ שתמיד מוחזר אלא אם כן כתבנו במפורש שלא יחזור.
- ה-stage השלישי הוא ה-sort שימיין את ה-documents שהגיעו אליו לפי גיל בסדר יורד.
- ה-stage הרביעי הוא ה-limit שיגביל את כמות ה-documents המוחזרים ל-3 הראשונים.
אמנם השימוש ב-aggregate במקרה הזה יצר פקודה ארוכה יותר ממה שניתן ליצור בלי aggregate, אבל ניתן לראות שהסדר שלה עוזר להבין שלב אחרי שלב מה בדיוק עשינו פה.
מכיון שה-stages מתבצעים אחד אחרי השני, כדאי להתחיל עם ה-match, כיון שהוא יגרום לכך של-stages הבאים יגיעו פחות documents מה שיעשה את העבודה יותר יעילה ומהירה.
מצד שני, צריך לשמור על סדר נכון של stages. כי אם למשל נשים את limit לפני sort לא נקבל את ה-top 3 שרצינו כי ה-limit יעביר הלאה רק שלוש documents לפני שהם ממוינים, ואז ה-sort יתבצע רק על ה-3 שעברו אליו. לכן סדר ה-stages חשוב מאוד.
למרות מה שכתבנו שכדאי לשים את match ראשון כדי שהפעולה תהיה יותר יעילה, לא כדאי לייעל את הפקודה על ידי ה-stage שנקרא project כי למרות שהוא מפחית את כמות השדות הוא לא מייעל את הפקודה. לכן כדאי לשים אותו לקראת הסוף.
את sort כדאי לשים לקראת הסוף, כיון שפעולת המיון היא פעולה כבדה ולכן כדאי שתפעל על כמה שפחות documents.
אז למה בעצם להשתמש ב-aggregate
אז ראינו שפקודה אמנם מאריכה את הקוד אבל יוצרת סדר. אבל יש עוד סיבה.
ראינו שעל ה-cursor שה-find מחזיר ניתן לעשות פעולות כמו למשל sort או limit. אבל עם aggregate ניתן לעשות הרבה יותר פעולות. נכון ל-mongoDB 6.0, שלושים ואחת פעולות:
חלק מהפעולות פה ניתן לעשות רק בעזרת aggregate.
פעולת group
אחת הפעולות השימושיות ביותר ב-aggregate היא פעולת group שמאפשרת לקבל מידע מהנתונים לפי קבוצות שאנחנו מגדירים את המכנה המשותף בהם.
למשל, נניח שאנחנו רוצים לראות כמה גברים מכל מדינה יש לנו, נשתמש בפקודה הבאה:
persons> db.persons.aggregate([
... { $match: {gender: 'male'} },
... { $group: { _id: {state: "$location.state"}, totalSum: {$sum: 1} } }
... ])פעולת ה-group מקבלת id_ שהוא בעצם הפרמטר שלפיו אנחנו מקבצים את התוצאות. במקרה הזה לפי מדינה. לפני שם השדה location יש סימן $ שאומר למונגו שמדובר בשדה שיש לנו והוא צריך להשתמש בערך שיש בשדה הזה.
כיון שעכשיו יש לנו קבוצות של נתונים, ניתן לבצע עליהם פעולות כמו למשל לספור כמה נתונים יש בכל קבוצה על ידי האופרטור sum. הביטוי בתוך sum אומר מה הוא הערך שצריך להוסיף עבור כל מסמך בקבוצה. במקרה שלנו עבור כל מסמך מוסיפים 1 לסכום ולכן בעצם סופרים את מספר המסמכים בכל קבוצה.
התוצאה שנקבל היא (יתכן שתקבלו תוצאה אחרת כי הוא מדפיס רק חלק מהרשימה ומאפשר לכתוב it אם אנחנו רוצים לראות את המשך הרשימה):
[
{ _id: { state: 'aust-agder' }, totalSum: 6 },
{ _id: { state: 'essonne' }, totalSum: 3 },
{ _id: { state: 'rutland' }, totalSum: 2 },
{ _id: { state: 'galway' }, totalSum: 3 },
{ _id: { state: 'gisborne' }, totalSum: 7 },
{ _id: { state: 'pernambuco' }, totalSum: 12 },
{ _id: { state: 'south australia' }, totalSum: 15 },
{ _id: { state: 'schwyz' }, totalSum: 4 },
{ _id: { state: 'county londonderry' }, totalSum: 1 },
{ _id: { state: "hawke's bay" }, totalSum: 7 },
{ _id: { state: 'buskerud' }, totalSum: 7 },
{ _id: { state: 'خراسان شمالی' }, totalSum: 3 },
{ _id: { state: 'کهگیلویه و بویراحمد' }, totalSum: 2 },
{ _id: { state: 'ardèche' }, totalSum: 2 },
{ _id: { state: 'donegal' }, totalSum: 3 },
{ _id: { state: 'fribourg' }, totalSum: 6 },
{ _id: { state: 'jura' }, totalSum: 12 },
{ _id: { state: 'west midlands' }, totalSum: 1 },
{ _id: { state: 'hertfordshire' }, totalSum: 3 },
{ _id: { state: 'گیلان' }, totalSum: 2 }
]נמשיך מאותה פקודה ונוסיף stage של מיון, sort, שימיין לנו את התוצאות לפי ה-totalSum מהגדול לקטן:
persons> db.persons.aggregate([
... { $match: {gender: 'male'} },
... { $group: { _id: {state: "$location.state"}, totalSum: {$sum: 1} } },
... { $sort: {totalSum: -1}}
... ])
[
{ _id: { state: 'midtjylland' }, totalSum: 28 },
{ _id: { state: 'hovedstaden' }, totalSum: 25 },
{ _id: { state: 'nordjylland' }, totalSum: 24 },
{ _id: { state: 'sjælland' }, totalSum: 24 },
{ _id: { state: 'tasmania' }, totalSum: 23 },
{ _id: { state: 'new south wales' }, totalSum: 23 },
{ _id: { state: 'australian capital territory' }, totalSum: 20 },
{ _id: { state: 'queensland' }, totalSum: 20 },
{ _id: { state: 'victoria' }, totalSum: 19 },
{ _id: { state: 'northern territory' }, totalSum: 19 },
{ _id: { state: 'syddanmark' }, totalSum: 19 },
{ _id: { state: 'prince edward island' }, totalSum: 16 },
{ _id: { state: 'newfoundland and labrador' }, totalSum: 16 },
{ _id: { state: 'alberta' }, totalSum: 16 },
{ _id: { state: 'hessen' }, totalSum: 16 },
{ _id: { state: 'zeeland' }, totalSum: 16 },
{ _id: { state: 'south australia' }, totalSum: 15 },
{ _id: { state: 'western australia' }, totalSum: 15 },
{ _id: { state: 'danmark' }, totalSum: 15 },
{ _id: { state: 'nunavut' }, totalSum: 15 }
]שימוש מתקדם ב-project stage
כמו שראינו לעיל, ה-stage שנקרא project נועד להחזיר לנו רק את השדות שאנו רוצים. ב-aggregation framework ניתן לעשות הרבה דברים עם project למשל לשנות את הנתונים המוחזרים וכן ליצור שדות חדשים.
ב-DB שלנו יש לכל מסמך שדה של location שבתוכו יש כמה שדות. לדוגמה:
location: {
street: '5108 south street',
city: 'cashel',
state: 'galway',
postcode: 45802,
coordinates: { latitude: '35.5726', longitude: '148.0944' },
timezone: { offset: '+2:00', description: 'Kaliningrad, South Africa' }
}אם למשל אנחנו רוצים עבור כל מסמך ב-DB להחזיר שדה חדש שנקרא fullAddress שמורכב מהטקסט שיש ב-city ולאחריו הטקסט של ה-street. נוכל לעשות את זה בצורה הבאה:
persons> db.persons.aggregate([
... {
... $project: {
... _id: 0,
... fullAddress: {$concat: ['$location.city', ' ', '$location.street']}
... }
... }
... ])
[
{ fullAddress: 'cashel 5108 south street' },
{ fullAddress: 'chipman 3193 king st' },
{ fullAddress: 'billum 2156 stenbjergvej' },
{ fullAddress: 'elazığ 2575 abanoz sk' },
{ fullAddress: 'toulouse 6952 rue abel-ferry' },
{ fullAddress: "l'abbaye 7425 route de genas" },
{ fullAddress: 'اسلامشهر 1347 شهید بهشتی' },
{ fullAddress: 'devonport 5523 cackson st' },
{ fullAddress: 'sakarya 7115 istiklal cd' },
{ fullAddress: 'fontaines-sur-grandson 6735 rue abel-hovelacque' },
{ fullAddress: 'shelbourne 9148 brock rd' },
{ fullAddress: 'arklow 6948 springfield road' },
{ fullAddress: 'unterallgäu buchenweg 196' },
{ fullAddress: 'dunboyne 3356 highfield road' },
{ fullAddress: 'sigerfjord olav nygards veg 1791' },
{ fullAddress: 'ryslinge 3635 koldingvej' },
{ fullAddress: 'le havre 3301 rue des abbesses' },
{ fullAddress: 'fredeikssund 9046 østervænget' },
{ fullAddress: 'seattle 2801 e sandy lake rd' },
{ fullAddress: 'inverness 9879 manor road' }
]נראה טוב.
עכשיו נערוך את שם העיר ככה שיתחיל עם אות גדולה. נשתמש לשם כך באופרטורים toUpper, substrCP, subtract, strLenCP. נציג את הקוד ואז נסביר:
persons> db.persons.aggregate([
... {
... $project: {
... _id: 0,
... fullAddress: {$concat: [
... {$toUpper: { $substrCP: ['$location.city', 0, 1]}},
... {$substrCP: [
... '$location.city',
... 1,
... {$subtract: [{$strLenCP: '$location.city'}, 1]}
... ]
... },
... ' ',
... '$location.street'
... ]}
... }
... }
... ])הטיפול בשם העיר מחולק לשני חלקים, הטיפול באות הראשונה והטיפול בשאר האותיות.
כדי להפוך את האות הראשונה לאות גדולה השתמשנו בקוד הבא:
{$toUpper: { $substrCP: ['$location.city', 0, 1]}},
האופרטור toUpper ממיר את הטקסט לאות גדולה. אבל אנחנו רוצים להמיר רק את האות הראשונה של העיר, ולכן השתמשנו באופרטור substrCP שמקבל טקסט, מיקום האות הראשונה וכמה אותיות להחזיר. וכך בעצם לקחנו מהאות הראשונה (מיקום 0) למשך אות אחת. שזה במילים פשוטות מחזיר את האות הראשונה. והאופרטור toUpper יקבל אותה ויהפוך אותה לאות גדולה.
הטיפול בשאר האותיות התבצע ע"י הקוד הבא:
{$substrCP: [
... '$location.city',
... 1,
... {$subtract: [{$strLenCP: '$location.city'}, 1]}
... ]
... },שוב השתמשנו באופרטור substrCP כדי להחזיר את שאר האותיות מלבד האות הראשונה. גם פה הוא מקבל טקסט, מאיזה אות להתחיל (במקרה שלנו מהאות השניה שהמיקום שלה הוא 1), וכמה אותיות לקחת.
מספר האותיות שיש לקחת משתנה בין עיר לעיר ולכן השתמשנו באופרטור subtract שמפחית מספר אחד מהשני ובאופרטור strLenCP שמחזיר את מספר האותיות שיש בטקסט. אז מספר האותיות שיש בטקסט פחות 1 הוא מספר האותיות שאנחנו רוצים לקבל (כל האותיות בשם העיר מלבד האות הראשונה).
קצת מורכב, אני יודע, אבל תקראו את זה לאט ותעברו שורה שורה וזה ישב טוב בראש. כל פקודה פה באמת פשוטה מאוד.
להלן התוצאה שמונגו החזיר:
[
{ fullAddress: 'Cashel 5108 south street' },
{ fullAddress: 'Chipman 3193 king st' },
{ fullAddress: 'Billum 2156 stenbjergvej' },
{ fullAddress: 'Elazığ 2575 abanoz sk' },
{ fullAddress: 'Toulouse 6952 rue abel-ferry' },
{ fullAddress: "L'abbaye 7425 route de genas" },
{ fullAddress: 'اسلامشهر 1347 شهید بهشتی' },
{ fullAddress: 'Devonport 5523 cackson st' },
{ fullAddress: 'Sakarya 7115 istiklal cd' },
{ fullAddress: 'Fontaines-sur-grandson 6735 rue abel-hovelacque' },
{ fullAddress: 'Shelbourne 9148 brock rd' },
{ fullAddress: 'Arklow 6948 springfield road' },
{ fullAddress: 'Unterallgäu buchenweg 196' },
{ fullAddress: 'Dunboyne 3356 highfield road' },
{ fullAddress: 'Sigerfjord olav nygards veg 1791' },
{ fullAddress: 'Ryslinge 3635 koldingvej' },
{ fullAddress: 'Le havre 3301 rue des abbesses' },
{ fullAddress: 'Fredeikssund 9046 østervænget' },
{ fullAddress: 'Seattle 2801 e sandy lake rd' },
{ fullAddress: 'Inverness 9879 manor road' }
]כפי שרואים, כל שם של עיר מתחיל באות גדולה כמו שרצינו.
רואים פה את הכח של project ואת האפשרויות שהוא נותן לנו.
שימוש באופרטור convert
האופרטור convert מאפשר המרה של מגוון דברים כגון המרה של תאריכים, המרה של מספרים/בוליאני/תאריכים ועוד ל-string ועוד. הכל נמצא כאן.
נראה דוגמה של המרה של תאריך.
persons> db.persons.aggregate([
... {
... $project: {
... _id: 0,
... age: '$dob.age',
... birthday: {$convert: {input: '$dob.date', to: 'date'}}
... }
... }
...
... ])
[
{ age: 47, birthday: ISODate("1971-01-21T20:36:16.000Z") },
{ age: 29, birthday: ISODate("1988-10-17T03:45:04.000Z") },
{ age: 59, birthday: ISODate("1959-02-19T23:56:23.000Z") },
{ age: 66, birthday: ISODate("1951-12-17T20:03:33.000Z") },
{ age: 30, birthday: ISODate("1987-10-20T11:33:44.000Z") },
{ age: 58, birthday: ISODate("1960-01-31T05:16:10.000Z") },
{ age: 34, birthday: ISODate("1984-03-10T22:12:43.000Z") },
{ age: 35, birthday: ISODate("1982-10-09T12:10:42.000Z") },
{ age: 29, birthday: ISODate("1988-11-08T00:18:59.000Z") },
{ age: 52, birthday: ISODate("1966-08-03T09:22:41.000Z") },
{ age: 46, birthday: ISODate("1972-04-23T04:31:25.000Z") },
{ age: 33, birthday: ISODate("1984-09-30T01:20:26.000Z") },
{ age: 48, birthday: ISODate("1970-02-18T12:38:36.000Z") },
{ age: 27, birthday: ISODate("1990-10-14T05:02:12.000Z") },
{ age: 45, birthday: ISODate("1973-08-26T00:11:58.000Z") },
{ age: 35, birthday: ISODate("1983-05-20T21:26:44.000Z") },
{ age: 47, birthday: ISODate("1971-06-24T07:03:58.000Z") },
{ age: 61, birthday: ISODate("1957-06-28T13:29:32.000Z") },
{ age: 48, birthday: ISODate("1969-10-22T08:07:25.000Z") },
{ age: 29, birthday: ISODate("1988-12-12T08:20:04.000Z") }
]ההמרה שלנו היא משדה של תאריך שהיה נראה כך:
dob: { date: '1971-01-21T20:36:16Z', age: 47 }
לשדה מסוג ISODate שהוא פורמט מקובל לשימוש בהרבה מערכות עבור תאריכים.
למונגו יש גם אופרטורים מקוצרים של המרות למשל במקום הדגומה האחרונה היה אפשר להשתמש באופרטור toDate באופן הבא:
persons> db.persons.aggregate([
... {
... $project: {
... _id: 0,
... age: '$dob.age',
... birthday: {$toDate: '$dob.date'}
... }
... }
...
... ])והתוצאה היתה זהה.
שימוש ב-push, unwind, addToSet ליצירת מערך
בנושא הזה נשתמש ב-DB שנקרא tv ובו יש קולקשיין shows.
ניזכר איך נראה מסמך בקולקשיין הזה:
tv> db.shows.findOne() { _id: ObjectId("645dedfaf1bbd54a3d199ce7"), id: 3, url: 'http://www.tvmaze.com/shows/3/bitten', name: 'Bitten', type: 'Scripted', language: 'English', genres: [ 'Drama', 'Horror', 'Romance' ], status: 'Ended', runtime: 50, premiered: '2014-01-11', officialSite: 'http://bitten.space.ca/', schedule: { time: '22:00', days: [ 'Friday' ] }, rating: { average: 7.6 }, weight: 75, webChannel: null, externals: { tvrage: 34965, thetvdb: 269550, imdb: 'tt2365946' }, image: { medium: 'http://static.tvmaze.com/uploads/images/medium_portrait/0/15.jpg', original: 'http://static.tvmaze.com/uploads/images/original_untouched/0/15.jpg' }, summary: '<p>Based on the critically acclaimed series of novels from Kelley Armstrong. Set in Toronto and upper New York State, Bitten</b> follows the adventures of 28-year-old Elena Michaels, the world's only female werewolf. An orphan, Elena thought she finally nd her "happily ever after" with her new love Clayton, until her life changed forever. With one small bite, the normal life she craved taken away and she was left to survive life with the Pack.</p>', updated: 1534079818, _links: { self: {ef: 'http://api.tvmaze.com/shows/3' }, previousepisode: { href: 'http://api.tvmaze.com/episodes/631862' } }, 'main network': { id: 7, name: 'Space', country: { name: 'Canada', code: 'CA', timezone: 'America/Halifax' } } }
לכל מסמך יש שדה שנקרא genres ובו מערך של ז'אנרים שאותו סרט מתאים אליהם.
עכשיו אני רוצה להשתמש ב-group כדי לקבל רשימה של סרטים לפי שפה ולכל שפה אני רוצה רשימה של כל הז'אנרים שלה.
אם אני אשתמש רק באופרטור push כמו בדוגמה הזו:
db.shows.aggregate([
{
$group: {
_id: { language: '$language'},
allGenres: {$push: '$genres'},
}
}
])אני אקבל בשדה allGenres מערך של מערכים כי האופרטור push לוקח מכל מסמך את השדה genres ודוחף את התוכן שלו למערך. וכיון שהתוכן שלו הוא כבר עכשיו מערך לכן נקבל מערך של מערכים.
כדי למנוע את זה נשתמש ב-stage שנקרא unwind שהוא לוקח כל מסמך ועבור כל ערך במערך שנעביר לו הוא מחזיר מסמך נפרד רק עם ערך אחד.
למשל אם יש לנו מסמך שבשדה genres יש לו מערך עם שני ערכים, אז הוא יחזיר לנו שני מסמכים. לדוגמה:
db.shows.aggregate([
{ $unwind: '$genres'},
])
{
_id: ObjectId("645dedfaf1bbd54a3d199ced"),
id: 8,
url: 'http://www.tvmaze.com/shows/8/glee',
name: 'Glee',
type: 'Scripted',
language: 'English',
genres: 'Drama',
…
},
{
_id: ObjectId("645dedfaf1bbd54a3d199ced"),
id: 8,
url: 'http://www.tvmaze.com/shows/8/glee',
name: 'Glee',
type: 'Scripted',
language: 'English',
genres: 'Music',
…
}רואים שמדובר על אותו מסמך, אבל בשדה genres כל פעם יש לו רק ערך אחד.
נחזור לענייננו, נוסיף את ה-stage של unwind ונקבל את הפקודה הבאה:
tv> db.shows.aggregate([
... { $unwind: '$genres'},
... { $group: {
... _id: { language: '$language'},
... allGenres: {$push: '$genres'},
... }
... }
... ])
[
{
_id: { language: 'Japanese' },
allGenres: [
'Drama', 'Action',
'Anime', 'Horror',
'Anime', 'Fantasy',
'Horror', 'Anime',
'Horror', 'Supernatural',
'Drama', 'Anime',
'Thriller', 'Mystery'
]
},
{
_id: { language: 'English' },
allGenres: [
'Drama', 'Horror', 'Romance', 'Drama',
'Action', 'Crime', 'Drama', 'Science-Fiction',
'Thriller', 'Drama', 'Crime', 'Thriller',
'Drama', 'Thriller', 'Espionage', 'Action',
'Adventure', 'Science-Fiction', 'Drama', 'Music',
…עכשיו קיבלנו מערך עם ערכים כמו שרצינו, אבל יש פה עדיין בעיה שיש ערכים שחוזרים על עצמם. הסיבה לכך היא שפקודת push מכניסה כל ערך בלי לבדוק אם הוא כבר קיים. אם אנחנו רוצים שלא יהיו כפילויות עלינו להשתמש באופרטור addToSet שעושה את אותה פעולה כמו push מלבד זה שהוא לא מכניס ערך שכבר קיים במערך:
tv> db.shows.aggregate([
... { $unwind: '$genres'},
... { $group: {
... _id: { language: '$language'},
... allGenres: {$addToSet: '$genres'},
... }
... }
... ])
[
{
_id: { language: 'English' },
allGenres: [
'Supernatural', 'Romance',
'History', 'War',
'Thriller', 'Crime',
'Fantasy', 'Action',
'Drama', 'Music',
'Western', 'Comedy',
'Medical', 'Science-Fiction',
'Horror', 'Legal',
'Mystery', 'Sports',
'Family', 'Espionage',
'Adventure'
]
},
{
_id: { language: 'Japanese' },
allGenres: [
'Anime',
'Horror',
'Action',
'Drama',
'Supernatural',
'Thriller',
'Fantasy',
'Mystery'
]
}
]פעולות נוספות על מערך slice, size
לפעמים אנחנו רוצים לקחת רק חלק מהאיברים במערך. לצורך כך יש את האופרטור slice. יש לאופרטור הזה שתי אפשרויות.
בראשונה הוא מקבל רק את שם המערך וכמה איברים להחזיר מהתחלה או מהסוף. לדוגמה כדי לקבל את האיבר הראשון בכל מערך נכתוב:
tv> db.shows.aggregate([
... { $project: {
... _id: 0,
... severalGenres: {$slice: ['$genres', 1]},
... }
... }
... ])וכדי לקבל את האיבר האחרון בכל מערך נכתוב ערך שלילי:
tv> db.shows.aggregate([
... { $project: {
... _id: 0,
... severalGenres: {$slice: ['$genres', -1]},
... }
... }
... ])אם אנחנו מעוניינים ביותר מאיבר אחד פשוט נשנה את ה-1 למספר שאנו רוצים.
באפשרות השניה של האופרטור הזה אנחנו כותבים שלושה פרמטרים. שם המערך, מאיזה איבר במערך, וכמה איברים. לדוגמה אם אנחנו רוצים 3 איברים החל מהאיבר השני אז נכתוב כך:
tv> db.shows.aggregate([
... { $project: {
... _id: 0,
... severalGenres: {$slice: ['$genres', 1, 3]},
... }
... }
... ])
[
{ severalGenres: [ 'Horror', 'Romance' ] },
{ severalGenres: [ 'Action', 'Crime' ] },
{ severalGenres: [ 'Science-Fiction', 'Thriller' ] },
…המיספור של המקום הראשון במערכים הוא 0 ולכן כתבתי 1 כדי להתחיל מהמקום השני.
אם אנחנו רוצים לקבל את אורך המערך נשתמש באופרטור size:
tv> db.shows.aggregate([
... { $project: {
... _id: 0,
... numOfGenres: {$size: '$genres'},
... }
... }
... ])
[
{ numOfGenres: 3 }, { numOfGenres: 2 },
{ numOfGenres: 3 }, { numOfGenres: 4 },
{ numOfGenres: 3 }, { numOfGenres: 3 },
…סינון איברים במערך לפי תנאי ע"י filter
האופרטור filter מאפשר לנו לסנן ערכים ממערך ע"י תנאי. לצורך הדוגמה נשתמש בקולקשיין books שיצרנו בעבר. נוסיף לכל מסמך שדה שנקרא details ובו יש מערך של אובייקטים. כל אובייקט מתאר את הספר מבחינת המצב שלו והמחיר שלו. לדוגמה:
{
_id: ObjectId("6666c4bc2235e7545e1f2a56"),
title: 'The Blocksize war',
description: 'This book covers Bitcoin’s blocksize war power',
details: [
{ item_id: 1, condition: 9, price: 49 },
{ item_id: 2, condition: 7, price: 39 }
]
}עכשיו נשתמש ב-filter כדי למצוא את כל הספרים שהם במצב 8 ומעלה:
books> db.books.aggregate([
... { $project: {
... _id: 0,
... goodDetails: {$filter: {input:'$details', as: 'dtls', ... cond: {$gte: ['$$dtls.condition', 8]}},
... }
... }
... }
... ])
[
{ goodDetails: [ { item_id: 1, condition: 9, price: 49 } ] },
{
goodDetails: [
{ item_id: 3, condition: 10, price: 120 },
{ item_id: 5, condition: 8, price: 99 }
]
}
]נסביר על הפרמטרים של האופרטור filter.
בפרמטר input נכתוב את שם השדה שאנחנו רוצים לבדוק.
בפרמטר as אנחנו נותנים שם (כמו שם של משתנה) שהוא יהיה השם של כל איבר במערך. כשהפילטר פועל הוא עובד כל פעם על איבר אחד, אז פה אנחנו נותנים לו שם שבו נשתמש בפרמטר הבא.
בפרמטר cond אנחנו כותבים את התנאי. במקרה שלנו השתמשנו באופרטור gte שזה גדול או שווה. ואז במערך שהוא מקבל השתמשנו בשם שקבענו בפרמטר הקודם אבל עם קידומת של $$. הסיבה שיש שני סימני דולר היא שאם נשתמש רק באחד מונגו יחשוב שמדובר על שם של שדה במסמך כמו שאנחנו משתמשים תמיד. אז אנחנו משתמשים בשני סימני דולר וזה אומר למונגו להשתמש בשם שקבענו בפרמטר as. אז השם dtls מייצג כל פעם איבר במערך, ואנחנו רוצים לבדוק את הערך של השדה condition באיבר.
חלוקת המידע לקבוצות ע"י האופרטור bucket
האופרטור bucket מאפשר לנו לחלק את המידע לקבוצות לפי אחד הנתונים.
נראה דוגמה ונסביר:
persons> db.persons.aggregate([
... { $bucket: {
... groupBy: '$dob.age',
... boundaries: [0, 20, 40, 60, 80, 120],
... output: {
... sumOfPersons: { $sum: 1},
... averageAge: { $avg: '$dob.age'}
... }
... }
... }
... ])
[
{ _id: 20, sumOfPersons: 1778, averageAge: 29.920697412823397 },
{ _id: 40, sumOfPersons: 1894, averageAge: 49.63305174234424 },
{ _id: 60, sumOfPersons: 1328, averageAge: 66.55798192771084 }
]בדוגמה הזו חילקנו את נתוני האנשים לפי הגיל. הנתון שעל פיו מחלקים את הנתונים מוגדר בפרמטר groupBy.
לאחר מכן, בשדה boundaries קבענו את הגבולות. קבוצה ראשונה תהיה מגיל 0 ועד 20. קבוצה שניה מגיל 20 ועד 40 וכן הלאה.
בשדה output קבענו מה השדות שאנחנו רוצים לראות בכל קבוצה. במקרה שלנו יצרנו שדה שסוכם את מספר האנשים בקבוצה ע"י האופרטור sum, ושדה שמראה את הגיל הממוצע ע"י האופרטור avg.
פקודה שימושית נוספת היא bucketAuto שמבקשת ממונגו לחלק את הנתונים בצורה אוטומטית לפי מה שנראה למונגו. נראה דוגמה:
persons> db.persons.aggregate([
... { $bucketAuto: {
... groupBy: '$dob.age',
... buckets: 4,
... output: {
... sumOfPersons: { $sum: 1},
... averageAge: { $avg: '$dob.age'}
... }
... }
... }
... ])
[
{
_id: { min: 21, max: 35 },
sumOfPersons: 1315,
averageAge: 27.44866920152091
},
{
_id: { min: 35, max: 49 },
sumOfPersons: 1292,
averageAge: 41.4264705882353
},
{
_id: { min: 49, max: 63 },
sumOfPersons: 1349,
averageAge: 55.532246108228314
},
{
_id: { min: 63, max: 74 },
sumOfPersons: 1044,
averageAge: 68.06704980842912
}
]כפי שרואים, השדה boundaries הוחלף עם השדה buckets ובו קבענו כמה קבוצות אנחנו רוצים. מונגו בצורה אוטומטית החליט מה יהיו הגבולות בכל קבוצה וכן מה יהיה ה-id של כל קבוצה. הוא בחר בצורה הגיונית שה-id יכיל את הגיל המינימלי והמקסימלי בקבוצה.
שמירת המידע המתקבל מ-aggregate ע"י אופרטור out
אפשר בקלות לשמור את המידע שמתקבל מ-aggregate בקולקשיין חדש ע"י האופרטור out.
למשל בדוגמה של ה-bucket זה יראה ככה:
persons> db.persons.aggregate([
... { $bucket: {
... groupBy: '$dob.age',
... boundaries: [0, 20, 40, 60, 80, 120],
... output: {
... sumOfPersons: { $sum: 1},
... averageAge: { $avg: '$dob.age'}
... }
... }
... },
... { $out: 'buckets' },
... ])
persons> show collections
buckets
persons
persons> db.buckets.find()
[
{ _id: 20, sumOfPersons: 1778, averageAge: 29.920697412823397 },
{ _id: 40, sumOfPersons: 1894, averageAge: 49.63305174234424 },
{ _id: 60, sumOfPersons: 1328, averageAge: 66.55798192771084 }
]לסיכום
למדנו על האופרטורים העיקריים של aggregation framework ויש כמובן עוד רבים שלא הזכרנו. אפשר למצוא הכל בדוקומנטציה הרישמית. כדאי מאוד לתרגל את השימוש ב-aggregate כדי לקבל ניסיון והבנה של מה ניתן לעשות עם זה.
פרק 10: קצת על ניהול מערכת MongoDB
מה משפיע על ביצועי המערכת
מגוון דברים משפיעים על ביצועי המערכת. חלקם בשליטת המפתחים וחלקם בשליטת מנהל המערכת (DBA).
בשליטת המפתחים:
- השאילתות והפקודות שאנו כותבים משפיעים על ביצועי המערכת וצריך לכתוב אותם בצורה נכונה ואפקטיבית.
- לאינדקסים יש השפעה גדולה על הביצועים
- ל-schema (סוגי השדות) יש השפעה גדולה. אם כל פעולה דורשת המרות של נתונים זה כמובן ישפיע לרעה על ביצועי המערכת. כדאי לכתוב את הנתונים ככה שנוכל להשתמש בהם כמה שיותר קרוב לצורה בה הם מאוחסנים.
בשליטת ה-DBA:
- החומרה והרשת. כמה שהחומרה טובה ויותר והרשת מהירה יותר נקבל ביצועים טובים יותר
- Sharding
- Replica Set
על שני האחרונים נדבר בפסקאות הבאות.
מהם Capped Collections
ה-capped collections הם קולקשיינים מיוחדים שצריך ליצור אותם באופן מפורש ובהם אתה מגדיר מראש הגבלה על כמות הנתונים שהם יכולים להכיל. ברגע שנכנסים נתונים חדשים שגורמים לקולקשיין לעבור את הגודל המקסימלי, הנתונים הישנים ימחקו.
קולקשיין כזה מתאים למשל ללוגים שתופסים הרבה מקום ולאחר זמן אין לנו צורך בלוגים הישנים. או למשל למנגנון cashing שבו אנחנו רוצים שמידע מסוים יהיה זמין לנו לזמן מסוים ולאחר זמן כבר אין לנו צורך בו אלא במידע אחר עדכני יותר.
כדי ליצור capped collections נשתמש בפקודה הבאה:
persons> db.createCollection("logs", {capped: true, size: 10000}) { ok: 1 }
שם הקולקשיין הוא logs, והגודל הוא 10000 bytes.
ניתן גם לציין מה מספר המסמכים המקסימלי שהקולקשיין יכול להכיל בצורה הבאה:
persons> db.createCollection("cache", {capped: true, size: 10000, max: 15}) { ok: 1 }
בדוגמה הזו כמות המסמכים המקסימלית היא 15.
נקודה חשובה ביחס ל-capped collections היא שהמידע מוחזר תמיד בסדר שבו המידע הוכנס.
לדוגמה, אם נכניס 2 לוגים:
persons> db.logs.insertOne({text: "first log"})
{
acknowledged: true,
insertedId: ObjectId("667b37f18ad2251ca3f174b4")
}
persons> db.logs.insertOne({text: "second log"})
{
acknowledged: true,
insertedId: ObjectId("667b37f98ad2251ca3f174b5")
}ואז ניצור שאילתא שמחזירה את כל המסמכים:
persons> db.logs.find()
[
{ _id: ObjectId("667b37f18ad2251ca3f174b4"), text: 'first log' },
{ _id: ObjectId("667b37f98ad2251ca3f174b5"), text: 'second log' }
]נראה שהם חוזרים בסדר בה הוכנסו.
כשנכניס את המסמך שכבר עובר את הגבלת המקום של הקולקשיין ימחק המסמך הישן ביותר.
שימוש נכון ב-capped collections יכול להועיל מאוד למערכת מבחינת ביצועים ולמנוע עומס מידע שאין בו צורך.
מהו Replica Set
כאשר אנחנו כותבים פקודה למונגו היא מגיעה ל-MongoDB Server והוא מבצע אותה על ה-Primary Node. זה בעצם השרת הראשי ששומר את הנתונים.
במערכות אמיתיות, מנהל המערכת לא יסתפק רק ב-node אחד לשמירת הנתונים ויצור עוד nodes שגם בהם ישמרו הנתונים והם יקראו secondary nodes. הנתונים בעצם ישוכפלו בכל node. כל ה-nodes ביחד נקראים Replica Set.
ה-MongoDB Server יתקשר תמיד עם ה-Primary Node והוא ידאג לשכפל את הנתונים על ה-secondary nodes באופן אסינכרוני. מה שאומר שהנתונים לא משוכפלים מיידית ברגע כתיבתם אבל ישוכפלו כמה שיותר מהר.
הסיבה שאנחנו רוצים יותר מ-node אחד היא שבמקרה שה-Primary Node נפל מכל סיבה שהיא אחד מה-secondary nodes יתפוס פיקוד ויהפוך להיות ה-Primary Node והמערכת שלנו תמשיך להיות פעילה.
יתרון נוסף של Replica Set הוא שע"י קינפוג נכון של המערכת זה יכול לשפר את ביצועי קריאת הנתונים ע"י פיזור הבקשות בין ה-nodes. לעומת זאת כתיבת הנתונים תמיד תעבור דרך ה-Primary Node ולכן לא ניתן לשפר ביצועים של כתיבה ל-DB ע"י Replica Set.
מהו Sharding
במילה sharding הכוונה להגדלת ה-DB מבחינה רוחבית כך שבעצם הנתונים לא מוכפלים אלא יש עוד מקום לנתונים נוספים. ב-sharding אנחנו בעצם מוסיפים שרתים נוספים שבהם ישמר עוד מידע, וכך בעצם המידע שלנו מפוצל בין כמה שרתים. בד"כ כל shard יהיה Replica Set כך שבעצם כל שרת הוא קבוצת שרתים שמחזיקים את אותו המידע.
כשהמידע מחולק על פני מספר שרתים יש צורך ברכיב נוסף שידע להפנות את הבקשות ל-shard הנכון. לרכיב הזה קוראים mongos והוא משמש כראוטר לבקשות. הוא צריך לדעת לאיזה shard לפנות בפעולת כתיבה מסוימת ולאיזה shard לפנות בפעולת קריאה מוסוימת.
הדרך הטובה לבחור לאיזה shard לפנות היא ע"י shard key שהוא בעצם אחד השדות במסמכים שאנחנו בוחרים בו לתפקיד זה. צריך לעשות החלטה שקולה כדי להחליט באיזה שדה לבחור כי צריך שהשדה יעזור ל-mongos להחליט בקלות לאיזה shard לגשת ואיך לחלק את המסמכים באופן שווה בין ה-shards.
אם למשל הרבה פעולות מתבצעות על שדה שנקרא name יכול להיות הגיוני לבחור בשדה name שיהיה ה-shard key.
עם זאת, יתכן מאוד שיהיו פקודות שבהם ה-shard key לא יעזור (כי הוא לא רלוונטי לאותה פקודה למשל) ואז mongos יפנה את הבקשה לכל ה-shards וכל אחד מהם יענה לו אם הבקשה רלוונטית אליו או לא. אותו shard שהפעולה נוגעת אליו כבר יבצע אותה.
כיום הדרך הטובה לעשות sharding היא ע"י שימוש בענן שבו יש שירות של מונגו ומאפשר scaling אוטומטי מה שמאחורי הקלעים יוצר לנו shards בלי שאנחנו צריכים לדאוג לזה בעצמנו. הענן הפופולארי הוא של MongoDB בעצמם ונקרא Atlas.
פרק 11: טרנזקציות
בפיסקה שדיברנו על אטומיות ראינו שמונגו מבטיח לנו אטומיות ברמת ה-document. לפעמים יש לנו צורך באטומיות של סדרה של פעולות.
תיאור מקרה
אם נחשוב למשל על המערכת של פייסבוק. נגיד שפייסבוק רוצים לתת אפשרות למשתמש למחוק את החשבון שלו, ומבטיחים לו שבפעולה זו נמחקים גם כל הפוסטים שהוא כתב.
בעיקרון מדובר על שתי פעולות, הראשונה מחיקת המשתמש שהוא כנראה יהיה בקולקשיין של users. והשניה מחיקת הפוסטים שהוא יצר, שהם כנראה יהיו בקולקשיין של posts.
בד"כ הפעולות האלו יעברו בהצלחה ולא תהיה שום בעיה. אבל במערכות אמיתיות אנחנו רוצים יותר ודאות. יש חשש שבאמצע פעולות המחיקה (שיכולות לקחת זמן אם המשתמש כתב הרבה) תהיה בעיה במערכת (שרת שנפל, הפסקת חשמל או כל דבר אחר) ואז יתכן מצב שהמשתמש נמחק אבל חלק מהפוסטים לא נמחקו. בפוסטים יש שדה של userId שמפנה ל-id של המשתמש שכבר לא קיים וזה כמובן דבר שלא בריא למערכת.
במקרה כזה אנחנו רוצים שפעולת המחיקה של המשתמש והפוסטים ביחד תהיה אטומית. או שהכל נמחק או ששום דבר לא נמחק. הדבר הזה אפשרי ע"י שימוש במנגנון שנקרא transaction.
רק נקדים ונאמר שטרנזקציות ניתנות לשימוש רק החל ממונגו 4.0 ומעלה. בנוסף מימוש המערכת חייב לכלול Replica Set (הסבר על זה ניתן בפרק הקודם).
יצירת טרנזקציה
נניח שלכל משתמש יש userName ייחודי.
const session = db.getMongo().startSession() const users = session.getDatabase('facebook').users const posts = session.getDatabase('facebook').posts session.startTransaction() users.deleteOne({userName: 'rafaelJan'}) posts.deleteMany({userName: 'rafaelJan'}) session.commitTransaction()
כל עוד הפקודה האחרונה לא רצה שאר הפקודות עוד לא התבצעו.
ה-session מאפשר לנו שכל הפקודות שנכתוב יהיו תחת קבוצה אחת ולא יצאו לפועל באופן מיידי אלא רק כאשר הפקודה commitTransaction תרוץ.
אז כמו שהוסבר לעיל, אם תוך כדי המחיקות תהיה בעיה בשרת ולא נצליח לסיים את כל מה שיש בטרנזקציה, מונגו ישחזר את מה שכבר בוצע כדי להביא אותנו לאותו מצב כמו לפני הפעולה. ככה שמובטח לנו שהכל התבצע או שכלום לא התבצע.