הקדמה
אני מתכנן לכתוב סידרה של פוסטים בנושא של machine learning.
כדי שיהיה אפשר בקלות לקרוא לפי סדר, בכותרת של כל פוסט אני אוסיף מספר.
אשתדל שהתוכן יהיה מדויק ונכון אבל לא בכתיבה פורמאלית וקשה, אלא בניסוח יותר קל לקריאה. אם משהו עדיין לא ברור מוזמנים לשאול בתגובות.
מה זה Machine Learning ?
Machine learning הוא תת-תחום בתוך בינה מלאכותית. בעברית הוא
נקרא "למידת מכונה" או "למידה חישובית". תחום זה זוכה לאחרונה
בפופלריות הולכת וגדלה.
מה שמיוחד בתחום הזה, היא האפשרות לפתח דברים שעד היום היה קשה מאוד
או בלתי אפשרי לעשות בתכנות רגיל. בתכנות רגיל, אנחנו אומרים למחשב מה לעשות
מההתחלה ועד הסוף. סט שלם של פקודות, כך שלכל מקרה יש תגובה ידועה מראש. ב-ML הרעיון הוא שהתוכנה משתפרת תוך כדי ריצה.
נסביר בגדול איך התהליך הזה קורה. התוכנה מְחַקַה את צורת הפעולה של המוח האנושי. ניקח
לדוגמה רכיבה על אופניים. בתחילת הלימוד זה קשה ויש הרבה טעויות. האדם
הלומד לרכב חושב הרבה על כל פעולה – על סיבוב הפדלים, על כיוון הכידון, על הבלמים
ועל כל דבר שהוא רואה בשביל. לאט לאט המוח לומד איך לכוון את הכידון בצורה נכונה
ומדוייקת יותר, איך לסובב את הפדלים בקצב קבוע, ואיך לבלום נכון. אחרי זמן מה, כל
זה כבר נהיה אוטומטי עד כדי כך שהרוכב כבר לא חושב על זה. הוא פשוט רוכב על
אופניים והמוח אפילו פנוי לחשוב על דברים אחרים. בעצם היה פה תהליך של למידה
ושיפור עד להגעה למצב של רכיבה מדויקת וחלקה.
תהליך דומה קורה ב-ML. בהתחלה האלגוריתם מנסה
לעשות את המשימה שהוטלה עליו ומשיג תוצאות לא כל כך טובות. הוא מחשב את השגיאה ולפי
השגיאה משנה חלק מהפרמטרים שמשפיעים על התוצאה ומבצע ניסיון נוסף. הוא מחשב שוב את השגיאה ושוב משנה חלק מהפרמטרים ומבצע נסיון נוסף. את
התהליך הזה הוא יכול לעשות עשרות, מאות ואפילו אלפי פעמים. תלוי באלגוריתם
ובמשימה.
כמו שהגדיר את זה יפה ג'פרי הינטון (Geoffrey Hinton) מי שנחשב לאחד האבות המייסדים של deep learning:
"Our relationship to computers has changed. Instead of programming them, we now show them, and they figure it out"
תחומים שונים ב-ML
ב-machine learning יש מספר תחומים, כאשר
הראשיים שבהם הם:
1.
Regression – חיזוי
ערכים, למשל כשרוצים לחזות מחיר של מניות.
2.
Classification – סיווג.
למשל כשרוצים לדעת מה יש בתמונה.
3.
Clustering – סיווג
לקבוצות. למשל כשרוצים לחלק את המשתמשים לקבוצות עם מאפיינים דומים אבל לא יודעים מראש
מה יהיו מאפייני הקבוצות
ויש כמובן תחומים נוספים.
לכל תחום יש מגוון מודלים, למשל:
1.
Multiple
linear regression
2.
Decision
Trees
3.
Artificial
Neural Network
חלק מהמודלים טובים לכמה תחומים.
לכל מודל יש אחד או יותר אלגוריתמים שמממשים אותו:
1.
C4.5 או CART בשביל Decision trees
2.
Backward
elimination או forward selection בשביל multiple linear regression
3.
Back
propagation בשביל artificial neural network
סוגי למידה
ב-ML ישנם כמה סוגים של למידה:
Supervised learning
או בעברית למידה מונחת, היא משימה שבה משתמשים במידע מתויג (labeled). למשל כשרוצים לדעת אם יש בתמונה כלב או חתול, אז משתמשים
בתמונות מתויגות כדי ללמד את האלגוריתם. הצורה הזו מתחלקת לשני מקרים:
Passive learning – הדוגמאות שניתנות למודל לא בשליטתו ונבחרים
ע"י אחרים.
Active learning – המודל משפיע על הדוגמאות שהוא מקבל כדי ללמוד.
במקרה הזה המודל ינסה להבין איפה הוא לא טוב וינסה לקבל דוגמאות באזור הזה כדי
להשתפר.
Unsupervised learning
או בעברית למידה לא מונחת, היא משימה שבה משתמשים במידע לא מתויג. מקרה
נפוץ ל-unsupervised learning הוא משימת clusterring.
יש גם מקרים שנקראים semi-supervised שבהם חלק מהדוגמאות
מתויגות (labeled) וחלק לא מתויגות. וזה דבר די נפוץ במציאות
כיון שלתת תיוג למידע זה לפעמים דבר יקר שדורש זמן ולכן יש לנו חלק מתויג וחלק לא.
Reinforcement learning
המודל הלומד מקבל פידבקים תוך כדי למידה וכך משפר את הלמידה. למשל
רובוטים הרבה פעמים צריכים מודלים מהסוג הזה. כיון שהם מנסים דברים ומתייגים אותם
כהצלחה או כשלון וכך משפרים את המודל שלהם.
תהליך בחירת המודל
אחד העקרונות ב-ML הוא ש"אין ארוחות
חינם" (no free lunch theorem in ML, Wolpert 2001). במילים פשוטות הכוונה
היא שאין אלגוריתם אחד שטוב יותר בכל המקרים מאלגוריתמים אחרים. תמיד יהיו מקרים שאלגוריתם אחר יהיה טוב יותר.
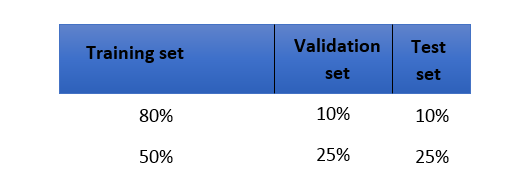
תהליך בחירת מודל ב-ML בדרך כלל נראה כך: מחלקים את ה-dataset לשלושה חלקים. Training set, validation set,
test set. מאמנים כל מיני מודלים שאנחנו רוצים לבחון על ה-training set. משנים את הפרמטרים של המודל (hyper-parameters) ובודקים את השיפור על ה-validation set. לאחר מכן כדי להעריך מהי השגיאה ה"אמיתית" (generalization error) של המודל שלנו, מריצים אותו על ה-test set.
חלוקות מקובלות:
במקרה שיש לנו כמות קטנה של data נחלק אותו
בצורה שונה כך שפחות data יוגדר כ-test set ויותר יוגדר ב-training set כדי שיהיה לנו מספיק data לצורך אימון המודל.
בפועל, הרבה פעמים מדלגים על שלב ה-validation
set ויוצרים רק training set ו-test
set.
תהליך אימון המודל מתבצע על ידי ריצות רבות של המודל תוך כדי שיפור
המשקלים לפי השגיאה המתקבלת עבור ה-training set. האיור הבא מתאר את
התהליך הזה:
כאשר:
·
x - הפרמטרים
הבלתי תלויים שנכנסים למודל.
· y - התוצאה
האמתית שידועה לנו מהנתונים שאיתם מאמנים את המודל (training
set).
· ŷ - התוצאה שהמודל חישב.
· f̂ - הפונקציה שהמודל יוצר. הפונקציה הזו משתנה בכל איטרציה לפי השגיאה.
ככל שהמודל איכותי יותר כך השגיאה שלו תקטן.
הערה כללית: מקובל לסמן את הדברים של המודל ע"י כובע (כמו ŷ או f̂), שבעצם מייצג שמדובר על
משהו משוערך ולא המידע האמיתי והמדויק.
איכות המודל
ישנם שלושה גורמים לשגיאה של המודל:
1.
רעש – noise
2.
הטיה – bias
3.
שונות – variance
רעש – הנתונים שיש לנו מכילים רעש כיון שתמיד יהיו עוד גורמים שמשפיעים
על התוצאה ושהמודל לא מתחשב בהם.
הרעש מתואר ע"י ה- Ɛ בביטוי
הבא:
y = fw(true)(x)+ε
כאשר y הוא התוצאה האמיתית ו-f הוא הפונקציה האמיתית (שמתארת בצורה מדויקת את y כתלות בקלט x לפי המשקל w)
Bias – הטיה. המודל שאנחנו יוצרים תלוי ב-training data שלנו. וכל פעם שנקבל סט אחר של training data נקבל מודל שונה. הממוצע של כל המודלים האלו
הוא בעצם המודל הסופי שלנו. השוני שיש בין המודל שלנו למודל האמיתי נקרא הטיה.
בגדול אפשר לומר שלמודל לא מורכב תהיה הטיה גדולה. ולמודול מורכב תהיה הטיה קטנה. והיא
מתוארת בביטוי הבא:
Bias(x) = fw(true)(x) - fŵ(x)
כאשר ŵ הוא המשקל המשוערך.
Variance – שונות. עד כמה שונה יהיה המודל שלנו עבור training data שונה. למשל עבור מודל פשוט מאוד (constant פשוט קו ישר) השונות תהיה קטנה. הקו יזוז קצת כלפי מעלה וכלפי מטה
אבל יחסית השונות תהיה קטנה. בגדול אפשר לומר שלמודל פשוט תהיה שונות קטנה, ולמודל
מורכב תהיה שונות גדולה.
הביטוי הפורמאלי של השגיאה מורכב משלושת מרכיבי השגיאה:
Average prediction error at xt = σ²+ [bias(fŵ(xt))]² + var(fŵ(xt))
על הרעש כאמור, אין לנו שליטה ולכן משתמשים במדד השגיאה MSE (mean square error) שלא כולל את הרעש:
MSE = bias² + var
אנחנו
שואפים להקטין את ה-bias וה-variance כמה שיותר כדי להקטין את
השגיאה.
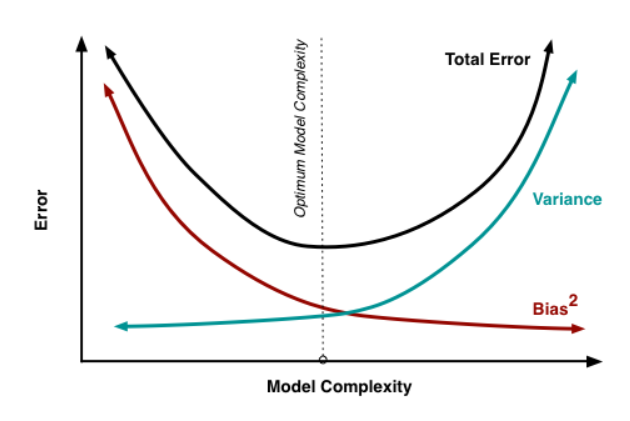
Bias – Variance tradeoff
כפי שראינו במודל מורכב נקבל הטיה קטנה ושונות גדולה, ואילו במודל
פשוט נקבל הטיה גדולה ושונות קטנה. ולכן אנחנו צריכים למצוא את הנקודה האופטימלית
שבה נקבל את השונות וההטיה הקטנים ביותר (הנקודה הזאת נקראת sweet
spot) כמתואר בגרף הבא (1):
אתגרים בבניית מודל
- Overfitting - אנחנו עלולים ליצור מודל שיהיה יותר מדיי מכוון ל-training set, וכשנשתמש בו למידע אחר השגיאה שלו תהיה גדולה. כדי לגלות overfitting נשתמש בערכים של bias ו-variance.
- רב ממדיות - אם יש
הרבה מאפיינים יש הרבה יותר מקום לטעויות. לכן נצטרך לבחור מה המאפיינים שהכי תורמים למודל ולהשתמש רק בהם.
- Imbalanced
dataset - אם במידע יש למשל 99% מסוג א ורק 1% לסוג ב. אז האלגוריתם עלול
לבנות מסווג שתמיד אומר שהתשובה היא א וכך הוא יהיה צודק ב99% מהמקרים. אלא
שבד"כ דווקא המקרים הנדירים הם החשובים לנו ושם נטעה ב100% מהמקרים.
- Concept drift – יש מקרים שבהם התפלגות
ה-dataset משתנה עם הזמן. לכן המודל צריך לדעת להסתגל מהר ובדייקנות. וצריך להיזהר
מ"רעש" שנראה כמו שינוי.
- תבניות לא אמיתיות - אנחנו עלולים לייחס בטעות משמעות לדברים אקראיים. לכן צריך להיזהר לא ליפול בפח של תבניות לא אמיתיות.
- הברבור השחור – דברים
שאנחנו חושבים שלא קיימים ולכן מתכננים את המודל כך שלא יהיה מוכן אליהם, ואז המודל טועה כשמתגלים דברים כאלו. יש שני סוגים כאלו. הראשון שניתן לגלות ע"י
אקסטרפולציה של המודל והשני שלא ניתן לגלות ע"י אקסטרפולציה. במציאות הסוג
השני קורה יותר. אבל מודלים של ML טובים דווקא לסוג הראשון.
- מסקנות - בדומה לתופעה שאנשים
שונים מגיעים למסקנות שונות מאותן העובדות, כך גם אלגוריתמים שונים (ולפעמים אפילו
אותו אלגוריתם בהרצות שונות) עלולים להגיע למסקנות שונות. וצריך להחליט באיזה
מודל לבחור.
מקורות
אם אהבתם, אשמח שתכתבו תגובה ותפיצו לחברים.